

Data for AI
Autonomous Data Products
Building AI-ready autonomous data products in minutes with Nextdata OS
The promise of modern data infrastructure was supposed to be simplicity. Yet building a single data product today still requires assembling a small army of specialists, coordinating across multiple teams, and navigating weeks of manual configuration work. Meanwhile, your AI initiatives wait in queue, your business users grow frustrated, and your engineering teams burn out on repetitive pipeline construction.
This coordination-heavy approach has reached a breaking point. Organizations pursuing AI at scale find themselves trapped in an exponential complexity spiral where each new use case demands the same lengthy coordination dance. The architecture that once served quarterly business reports now buckles under the velocity demands of real-time AI applications.
What's needed isn't faster coordination. It's the elimination of coordination overhead entirely through truly autonomous data products that can self-govern, self-orchestrate, and adapt to multiple consumption patterns without human intervention.
The exponential coordination problem
Traditional data product development operates like a complex manufacturing process requiring precise handoffs between specialized teams. Platform engineers define infrastructure patterns. Data engineers build transformation logic. Analytics engineers create semantic models. Governance teams establish access policies. Infrastructure teams manage deployments.
This model barely made sense when data served predictably static, well-defined use cases. A quarterly dashboard could justify an 8-week development cycle involving nine different specialists if it were going to be used for a year or two.
But AI applications have shattered this assumption. New AI use cases emerge overnight, and each demands its own specialized data preparation patterns:
Machine learning models require temporally accurate feature engineering with precise point-in-time correctness and complex windowing logic.
AI agents need streaming data with sub-second latency, real-time context awareness, and dynamic schema adaptation.
LLM applications require vectorized embeddings with preserved semantic relationships and optimized chunking strategies.
Recommendation engines demand multi-interval behavioral aggregations with sophisticated temporal modeling.
.png)
The result is slower time to production and even more complexity. Organizations attempting comprehensive AI strategies find themselves managing dozens of parallel development cycles, each requiring the same specialist coordination. The overhead doesn't scale linearly—it explodes exponentially as each new AI pattern multiplies the coordination overhead.
Why AI demands autonomous data products
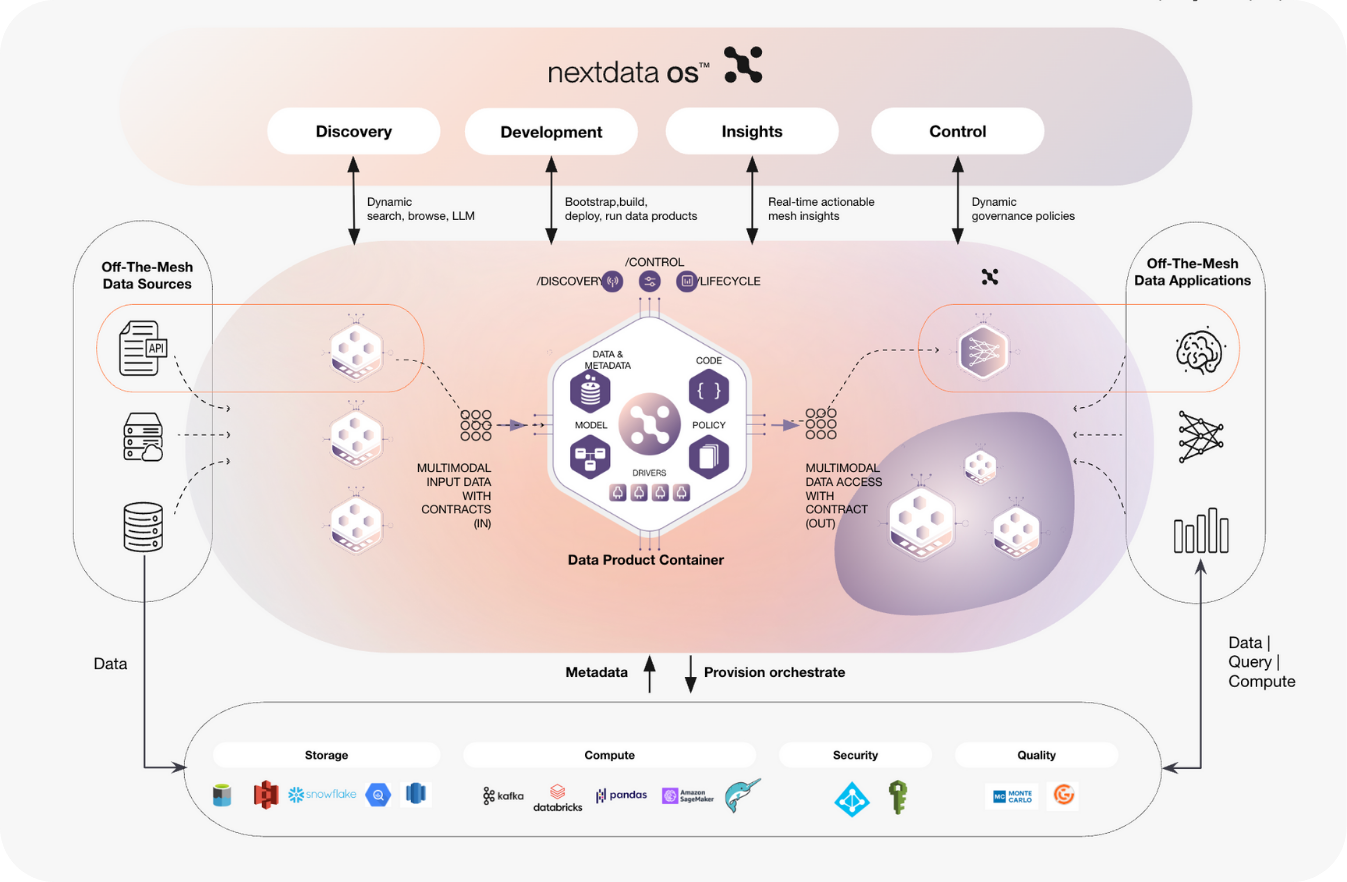
Autonomous data products represent a fundamental shift from coordination-dependent systems to self-governing autonomous entities. Think of them as intelligent, domain-aware data factories that understand their purpose, manage their own infrastructure, and adapt to changing consumption requirements without external orchestration.
Their foundation rests on several key principles:
Complete lifecycle autonomy: Each data product maintains full responsibility for its entire data lifecycle, from ingestion through governance to consumption interfaces. This eliminates the coordination dependencies that emerge when multiple teams must align on shared infrastructure decisions and operational procedures.
Infrastructure abstraction: Autonomous data products provision and manage their own cloud resources across multiple providers seamlessly. A single product might source from AWS S3, process on Databricks compute, store outputs in Azure Blob with Delta format, and serve through Snowflake—all unified under one autonomous management layer that handles provisioning, scaling, and optimization decisions.
Multimodal output: Rather than building separate pipelines for each consumption pattern, autonomous data products provide standardized access layers that simultaneously serve BI dashboards, ML training pipelines, AI agents, and LLM applications. The same underlying data product adapts its output format and delivery mechanism based on consumption requirements.
Computational governance: Security, access controls, data quality and compliance policies become integral architectural components rather than external overlay systems. This ensures governance scales naturally with the data product without requiring separate coordination processes.
Consider a customer-feedback data product that draws source data from multiple business domains and is widely used across the organization. It provisions its own cloud infrastructure, runs analysis on Databricks compute, stores output in Azure Blob with Delta format, pushes results to Snowflake, and sources data from S3 on AWS. All unified into one data product that spans multiple clouds seamlessly.
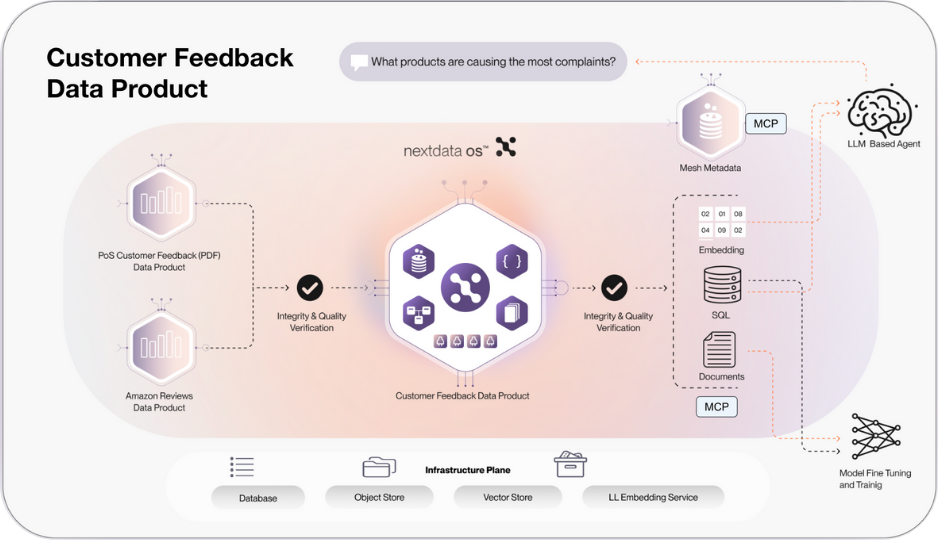
Nextdata generative copilot: multi-agent data product creation
Nextdata OS eliminates the manual specification overhead through a sophisticated multi-agent system that acts as an architectural co-pilot for data product creation. Instead of hand-crafting each component, you provide a data source and intent, and Nextdata OS generates complete, production-ready data product specifications.
Nextdata OS can support your choice of LLM’s, including Claude or ChatGPT, or you can use Nextdata’s own “Nexty AI” LLM.
The agent architecture consists of specialized components working in concert:
The Mesh Architect Agent analyzes your existing organizational patterns, scanning codebases and infrastructure configurations to understand domain boundaries, identify reusable architectural patterns, and ensure consistency with established organizational standards.
The Modeling Agent constructs semantic models by analyzing data structure, usage patterns, and business context. It generates governance-aligned schemas with appropriate business terminology, identifies relationship mappings, and creates LLM-compatible annotations for AI consumption.
The Implementation Agent produces executable transformation logic, defines input and output specifications, establishes data contracts with quality expectations, and generates deployable configurations compatible with your runtime infrastructure.
.png)
The generated output represents a complete data product specification: semantic models with rich metadata for discovery and AI consumption, data quality rules derived from statistical analysis and domain patterns, transformation logic optimized for target consumption patterns, standardized API interfaces for programmatic access, and governance policies aligned with organizational requirements.
The system generates all essential components: semantic models, input configurations, data quality expectations, transformation logic, output specifications, and governance policies. The resulting data products are containerized and fully autonomous—they manage their own compute resources, publish metadata, self-orchestrate, and provide standardized access patterns for downstream consumers including AI applications.

How to accelerate data product development step-by step with Nextdata OS
1. Describe your data product intent in natural language
In this step, we provide straightforward instructions to our copilot using natural language. We tell the system where the source data lives - in this case, Amazon reviews data - and give high-level context about what we’re trying to accomplish.
.png)
Using the text prompt, we can specify that we want to expose this data to Snowflake, apply all mesh-wide policies, and set schema expectations. That's it. No need to write detailed specifications or coordinate with platform engineers, data engineers, and governance teams upfront. The copilot takes our simple description and eliminates all that manual specification overhead that usually bogs down data product creation for weeks.
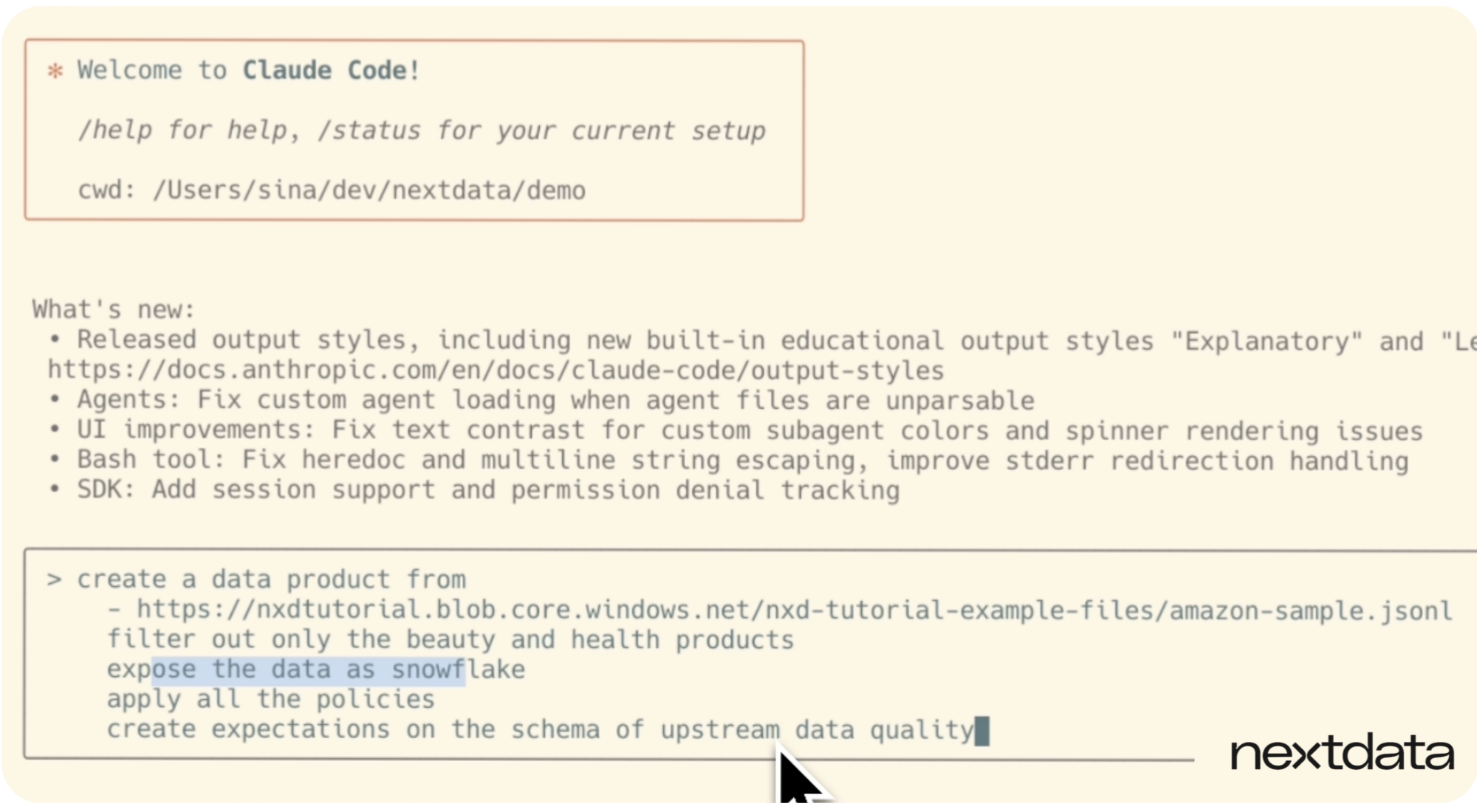
2. Watch Nextdata’s generative copilot fetch and reason about your source data
Once we submit the prompt, our multi-agent system kicks into action as an architectural copilot. The system automatically handles the data discovery work that usually takes our teams days to complete:
- Fetches the source data from our specified storage location
- Uses DocDB internally to reason about data samples and understand structure
- Analyzes existing organizational patterns from our logged-in user context
- Accesses our infrastructure credentials and configurations
We can watch in real-time as it reads parts of the data and reasons about it. The Mesh Architect Agent scans our existing patterns while the Modeling Agent analyzes the data structure. This eliminates those painful handoffs between teams where context gets lost and timelines stretch. Instead of manual data profiling sessions, the system understands our data automatically.
.gif)
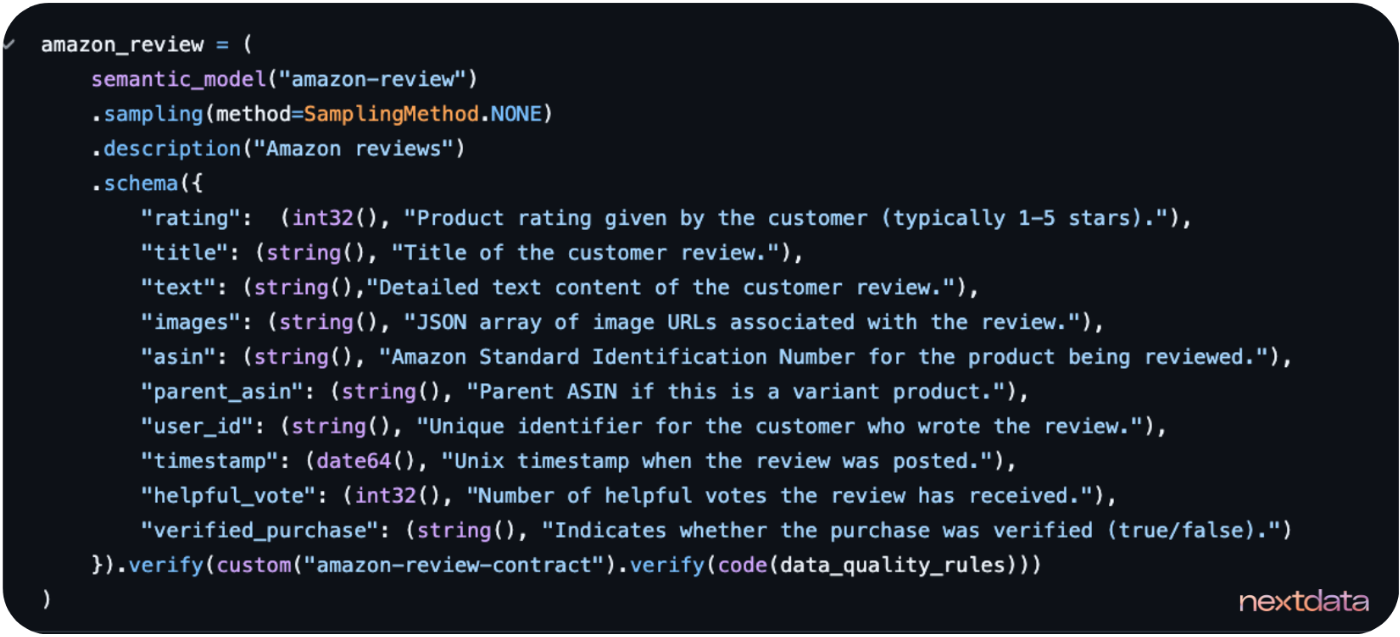
3. Generate complete semantic models automatically
Here's where the Modeling Agent really shines - it constructs semantic models by analyzing both the data structure and business context from our environment. We can see it generate governance-aligned schemas that actually make sense for our domain. The system produces:
- Schema definitions that reflect the actual data patterns
- Verification code for data quality checks
- Sampling logic appropriate for the data type
- Business terminology that aligns with our organizational standards
.gif)
Instead of spending weeks manually crafting schema definitions and coordinating with domain experts on business terminology, We get production-ready semantic models in minutes. The system understands this is Amazon reviews data and builds appropriate structures - products, reviews, ratings - without us having to spell out every detail.
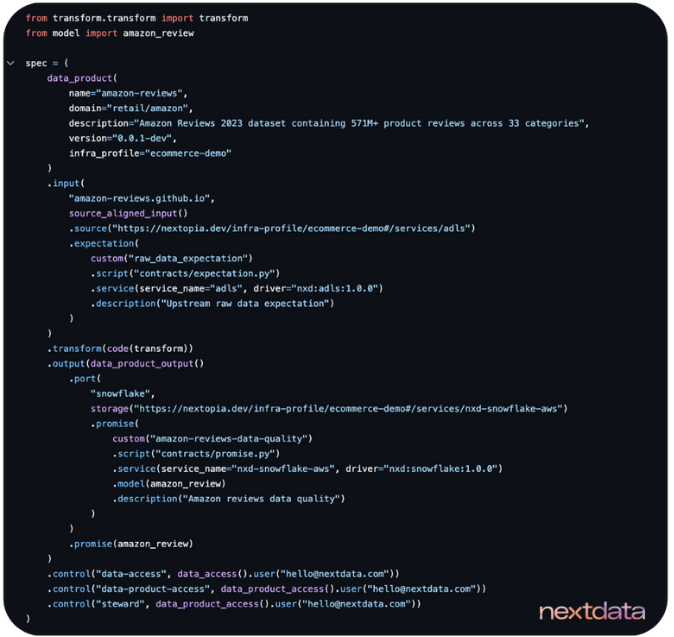
4. Review the generated transformation logic and specification file
The Implementation Agent delivers everything we need to deploy - executable transformation logic and complete specifications. Lets review three key components it generated:
- Transformation code that handles the data processing logic
- Semantic model with schema, verification, and sampling rules
- Spec file that brings everything together with inputs, outputs, and policies
.gif)
The transformation code shows it injected the Snowflake output we requested and structured the data appropriately. The spec file becomes our single source of truth, defining inputs from ADLS, transformation references, and output ports. It even suggests access permissions based on patterns from our other data products. This replaces those endless coordination meetings where teams try to align on data contracts and deployment specifications.
5. Launch the autonomous data product
In this step, we simply run the launch command and watch it take over. The system provisions everything needed without requiring infrastructure team coordination:
- Creates new schemas and tables in Snowflake
- Provisions appropriately sized compute warehouses
- Sets up monitoring and metadata publishing APIs
- Configures self-orchestration for upstream changes

We can see the provisioning happen in real-time. Once launched, this becomes a running service that manages its own compute resources, publishes metadata through standardized APIs, and handles orchestration automatically. No more waiting for infrastructure teams to provision resources or coordinating deployment schedules across teams.
6. Automate enforcement with built-in computational governance
Nextdata’s OS’ built-in computational governance system demonstrates how compliance becomes integral to the architecture rather than an external overlay. When we try to launch, the system automatically detects that my Amazon reviews data contains PII, which violates our global mesh policy against exposing PII data. The system:
- Blocks the launch automatically to prevent compliance violations
- Surfaces the specific policy conflict for my review
- Maintains organizational standards without manual governance review
- Requires me to explicitly address the policy violation before proceeding
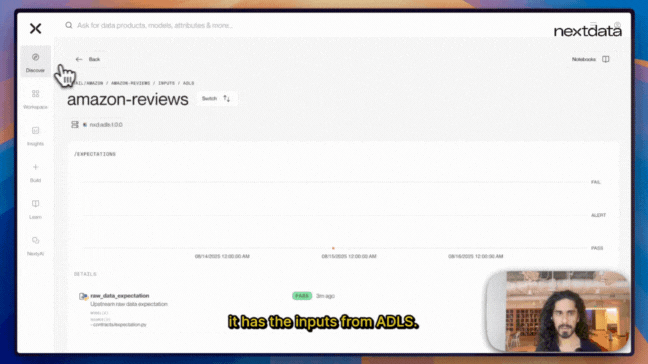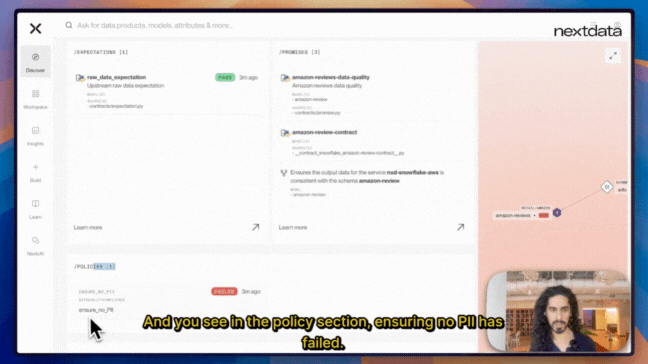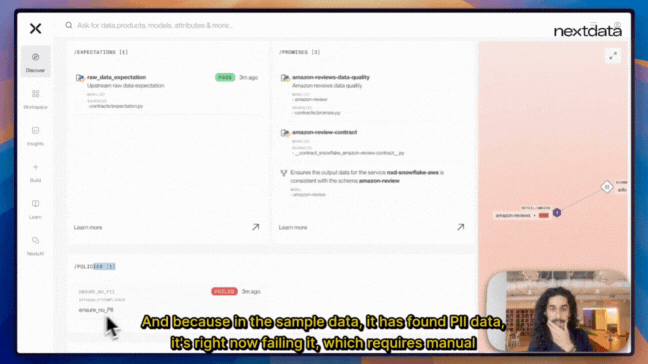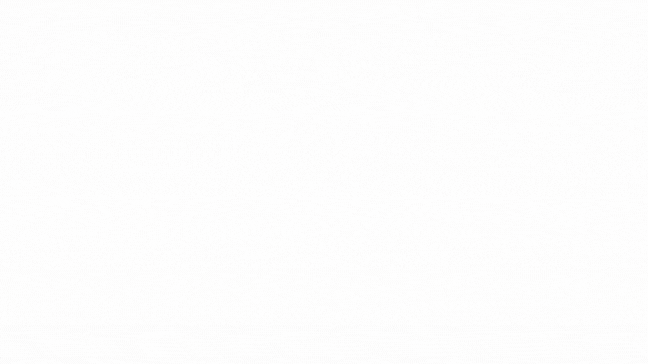
This shows computational governance in action - instead of waiting weeks for governance teams to review and approve my data product, the system enforces policies immediately. We know exactly what needs to be fixed and can address it right away, maintaining both compliance and development velocity.
Downstream impact: transforming data engineering practice
The shift to autonomous data products fundamentally alters how data teams operate and scale. Instead of spending weeks coordinating specialist input for each new data product, teams focus on higher-value architectural decisions and domain modeling work.
Development velocity increases dramatically. What previously required 8-10 weeks of coordination now happens in minutes of specification generation plus standard deployment time. Teams can iterate rapidly on data product designs, experiment with new consumption patterns, and respond quickly to changing business requirements.
Infrastructure complexity decreases through standardization. Autonomous data products follow consistent patterns for deployment, monitoring, and governance, reducing the cognitive overhead of managing heterogeneous pipeline architectures. Operations teams manage fewer distinct systems while supporting more data products.
Quality and governance improve through automation. Embedded governance and quality systems eliminate the manual oversight requirements that often become bottlenecks in traditional data product development. Compliance becomes a built-in standard rather than an external patch.
Conclusion
The transformation from coordination-heavy to autonomous data product development represents a fundamental business capability shift. Organizations that successfully adopt Nextdata OS intelligent data product generation discover competitive advantages that compound over time.
The organizations that successfully adopt autonomous data product generation will find themselves able to support hundreds of AI use cases without proportional increases in coordination overhead. They'll respond faster to market opportunities, experiment more freely with new data applications, and scale their data capabilities in alignment with business growth rather than coordination capacity.
The Coordination-Heavy Past: Traditional approaches required coordinating nine specialized roles across extended development cycles for each data product. AI initiatives stalled in handoff queues while market opportunities passed by. Engineering teams spent majority effort on repetitive pipeline construction rather than strategic innovation.
The Autonomous Present: Nextdata OS enables data product creation at business velocity rather than coordination velocity. Organizations support comprehensive AI strategies without exponential team scaling. Engineering focus shifts to strategic architectural decisions and competitive differentiation rather than repetitive coordination tasks.
The question facing data leaders isn't whether intelligent data product generation will become necessary—it's whether their organizations will lead this transformation or struggle to compete as coordination-heavy approaches prove inadequate for AI-scale business demands.
Nexty AI and our mult-agent architecture provide the foundation for this transformation today. The technology exists, the patterns are proven, and the competitive advantages are measurable. Organizations ready to move beyond coordination constraints can begin generating autonomous data products immediately, positioning themselves at the forefront of AI-driven business transformation.
Watch the full video of Nextdata OS' Generative Copliot on our Youtube channel. Schedule a customized demo of Nexty AI and Autonomous Data Products with one of our team members!
.jpg)

.jpg)
.png)




