

Data for AI
Events
Autonomous Data Products
Safe data for autonomous agents: 4 critical problems + solutions [Webinar recap]
In our recent webinar "Safe Data for Autonomous Agents," we explored the biggest data safety challenges companies face with AI agents. As AI agents become essential to business, safe data consumption is now a top priority for data teams and platform engineers. This webinar recap covers four key problems that can break AI projects and the solutions that fix them. These strategies can help data teams implement AI data governance, wrangle complex data pipelines for AI applications with autonomous data products, and accelerate AI agent deployment safely.
Watch the Full Webinar: https://www.youtube.com/live/EjWuzEzAe_g
Webinar Duration: 45 minutes
Presented by: Sina Jahan, Head of Product Engineering
Key takeaways: Four critical AI data safety problems solved
Problem 1: Complexity in data pipeline architecture
Organizations often build multiple separate pipelines when different teams need the same data for AI agents, ML models, and analytics. Each team creates its own pipeline because it needs different formats. Analytics teams need tables, AI agents require vector embeddings, and ML teams use files. This approach creates major operational and governance problems across the enterprise.
Key Impact Areas:
- Maintenance Overhead: requiring separate engineering teams for each pipeline's unique code and monitoring
- Governance Blind Spots: creating data flows that bypass quality checks and policy enforcement
- Resource Duplication: wasting compute and storage through redundant processing
The Solution: Organizations can solve this with multimodal autonomous data products that serve the same core data through different output ports within one logical boundary. This consolidates transformation logic while providing SQL endpoints, object storage, vector embeddings, and MCP (Model Context Protocol) endpoints for agents. The automatic orchestration delivers significant improvements to operations and architecture.
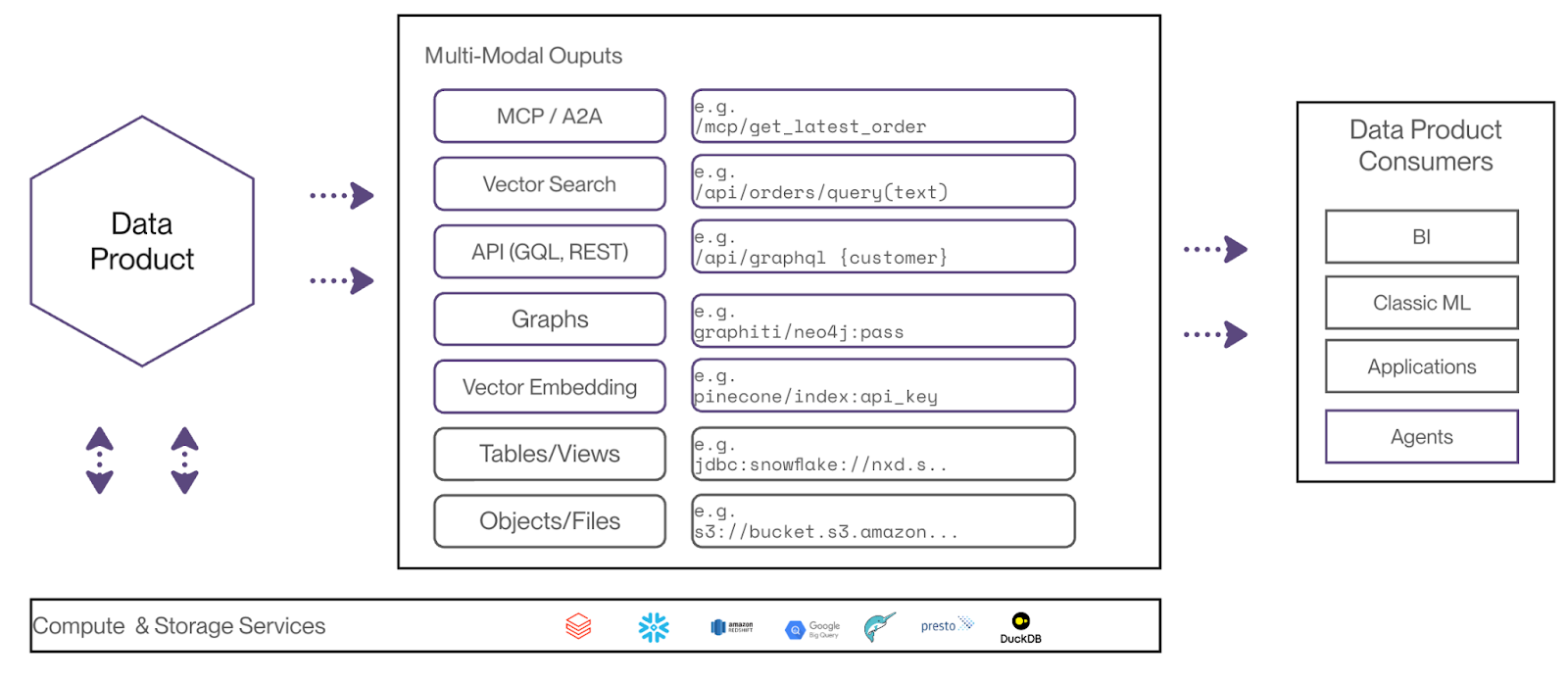
Business Outcomes:
- Unified Transformation Logic: consolidating business rules within a single maintainable boundary
- Reduced Infrastructure Complexity: eliminating redundancies and ad-hoc computation while maintaining flexible access
Problem 2: Enforcing quality through data product lifecycle management
Traditional data quality and testing approaches find problems after bad data has already reached AI systems. Observability tools only alert when issues occur, but can't prevent them. This allows poor-quality data to reach production before triggering alerts. The result? Reliability risks for AI agents that need high-quality inputs. These quality enforcement gaps create serious operational consequences.
Key Impact Areas:
- AI System Reliability Degradation: causing incorrect responses and user-facing failures
- Production Incident Escalation: requiring emergency response when quality issues hit live systems
- Consumer Trust Erosion: making downstream systems depend on unreliable data sources
The Solution: Autonomous data products implement data contracts with promises and expectations that check quality throughout the data product lifecycle. This prevents poor quality data from getting promoted to output ports before reaching consumers. Data quality SLAs are built in and applied at run-time, providing a systematic quality enforcement approach across domains.
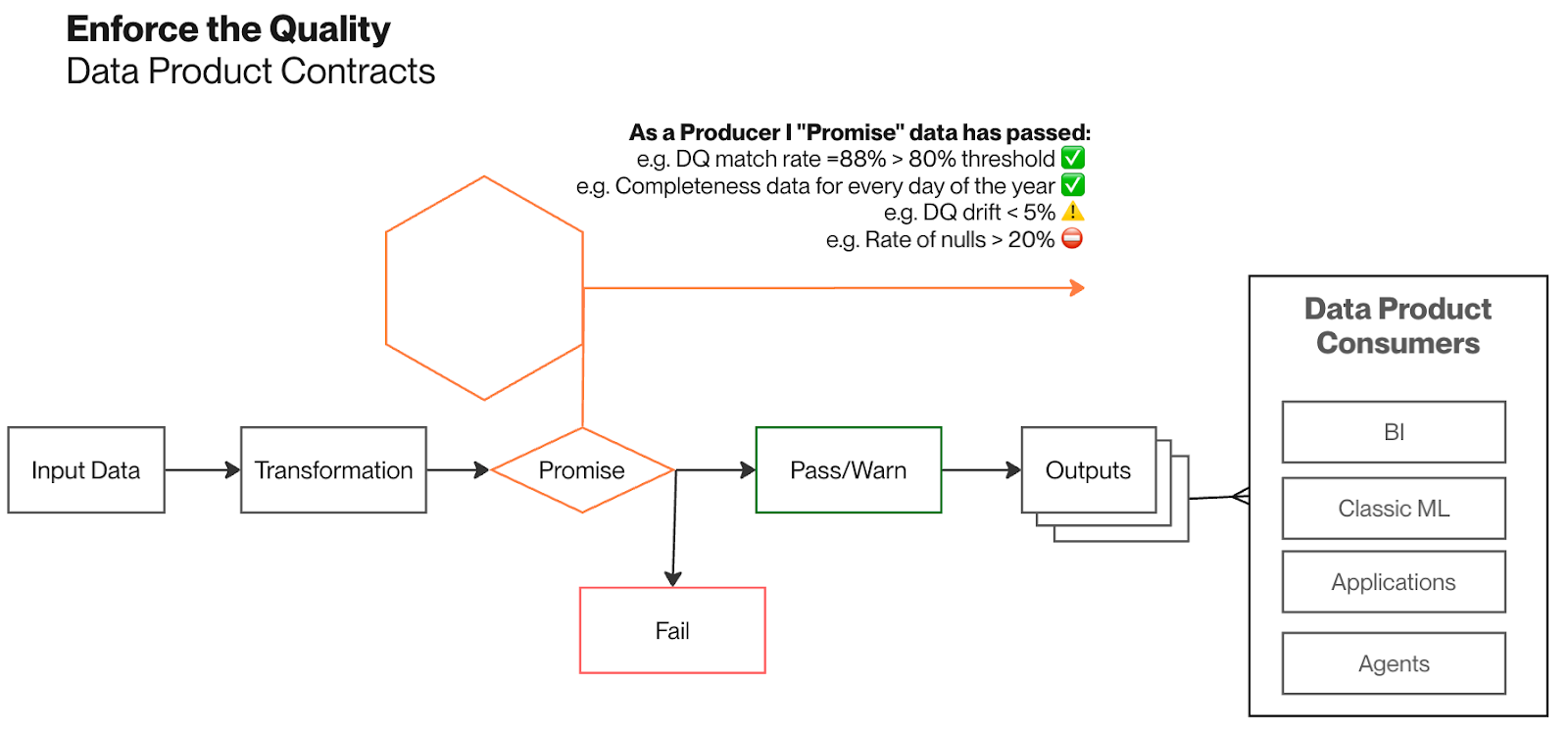
Business Outcomes:
- Proactive Quality Assurance: preventing quality issues through validation at promotion boundaries
- Systematic Promise Enforcement: ensuring completeness, freshness, and drift requirements before output availability
Problem 3: Enforcing compliance in federated governance scenarios
Platform teams struggle to ensure consistent governance across decentralized domains. Different teams manage data products using various technology stacks. Manual policy implementation creates gaps where teams may violate compliance requirements. This is especially critical for preventing PII from going to LLMs or ensuring data retention compliance. This federated governance challenge creates significant organizational risks.
Key Impact Areas:
- Compliance Risk Exposure: creating potential regulatory violations through inconsistent policy application
- Platform Team Governance Limitations: requiring manual monitoring across diverse stacks without systematic enforcement
- Federated Enforcement Gaps: complicating compliance verification across decentralized ownership models
The Solution: Autonomous Data Products’ provide built-in computational governance, enabling teams to deploy global policies-as-code that automatically apply to data products based on filter criteria. Policies execute locally within each data product environment during the lifecycle. They include configurable consequences such as stopping non-compliant products. This approach enables organizations to enforce local quality-control autonomously, verify globally, and deliver comprehensive compliance improvements.
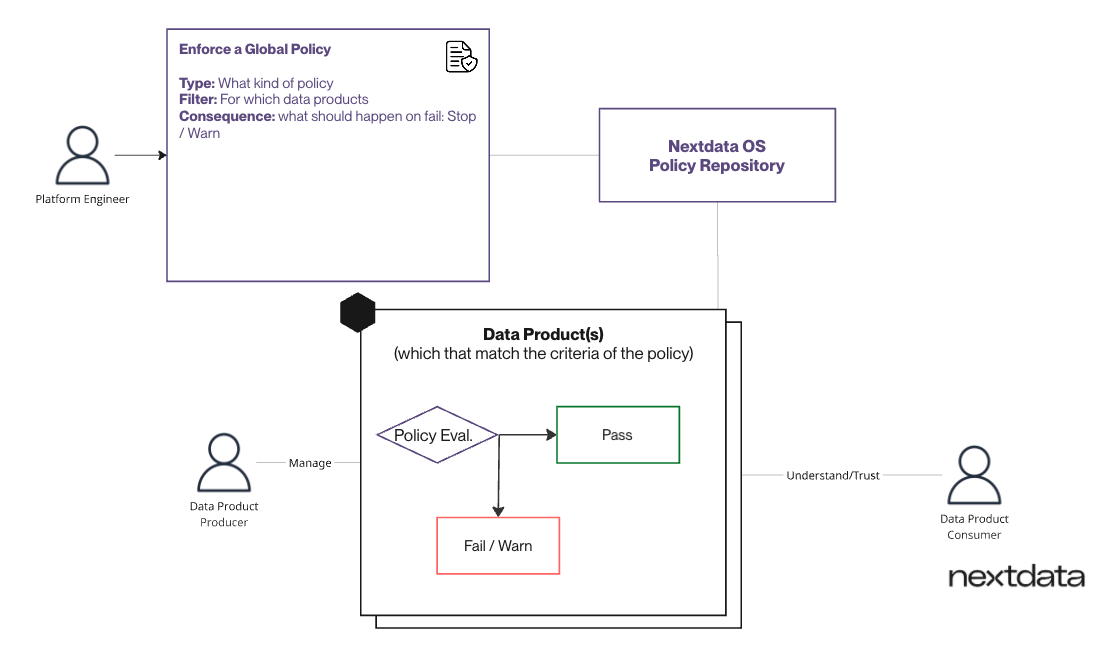
Business Outcomes:
- Automated Compliance Enforcement: eliminating manual interpretation through code-based validation
- Consistent Federated Application: ensuring uniform enforcement regardless of underlying technology stacks and domains
Problem 4: Data team productivity and specification generation
Data teams start from blank canvases when defining data contracts, quality rules, and outputs. This reduces team velocity and delays data product creation. Teams struggle with consumer-driven contract development. They lack starting points for understanding how downstream systems consume data and what promises they require. This specification overhead creates multiple development bottlenecks.
Key Impact Areas:
- Extended Development Cycles: delaying AI system implementation through prolonged planning phases
- Blank Canvas Paralysis: creating decision-making overhead without clear starting points
- Consumer-Driven Contract Gaps: requiring iterative refinement when specifications miss actual requirements
The Solution: Organizations can leverage Nextdata OS’ generative co-pilot to analyze existing usage patterns and generate initial autonomous data product specifications automatically. This system analyzes static code, consumer queries, and transformation logic. It suggests appropriate promises, expectations, and outputs, providing teams with 80% complete frameworks rather than empty templates. By removing the manual work and coordination overhead, Nextdata’s copilot creates substantial productivity gains for teams looking to build and deploy data products quickly.
Business Outcomes:
- Accelerated Development of Data Products and Specs: providing substantial starting frameworks rather than blank canvases
- Consumer-Driven Contract Generation: deriving requirements from actual downstream usage patterns
Timestamped Video Highlights
[00:05:00 - 06:30] - Why AI data safety matters: Investment trends and risk factors
[00:07:15 - 14:30] - Problem 1: Data pipeline complexity and multimodal solutions demonstration
[00:14:45 - 22:00] - Problem 2: Quality enforcement through data contracts with live examples
[00:22:15 - 33:00] - Problem 3: Global policy enforcement and computational governance demo
[00:33:15 - 45:30] - Problem 4: AI-powered specification generation with Nexty AI walkthrough
[00:45:45 - 50:00] - Q&A session covering implementation strategies and best practices
Ready to Solve These AI Data Safety Problems? See how Nextdata's autonomous data products eliminate pipeline complexity, enforce quality automatically, and accelerate AI agent deployment. Schedule a call with one of our team members for a customized walkthrough of Nextdata OS.
.jpg)

.jpg)
.png)




