

Data for AI
Autonomous Data Products
Data 3.0 needs an autonomous abstraction
Moving beyond the modern data stack with autonomous data products—the foundation for the next era of AI
AI now moves in sub-seconds; every new prompt creates a new intention that demands an entirely new set of data. Most enterprise data still moves in quarters. That mismatch, models and agents iterating at machine speed while data crawls through human-centric pipelines, is why so many GenAI efforts stall after a promising demo. This post lays out Data 3.0, a pragmatic architecture we’ve been refining with customers as we roll out Nextdata OS. The core idea: replace brittle, storage-centric plumbing with autonomous data products: Self-contained, semantic-first units that orchestrate, govern, and serve domain-centric data and context continuously to both humans and AI agents. It’s a shift as real as moving from bare metal to containers. Same operational problem, different domain: when complexity explodes, you encapsulate, define clean interfaces, and automate the coordination.
Why Data 2.0 is running out of road
The “modern data stack” (call it Data 2.0) was built for a dashboard world: batch ETL, manual integration, catalog and govern later. It succeeded at operationalizing analytics, but it faced three constraints that AI exposes instantly:
- Speed
Data 2.0 inevitably produces long delivery cycles. Waiting months to land the dataset, cleanse it, model it, catalog it, secure it, and certify it to publish doesn’t work when application behavior changes in milliseconds. - Scale (of impact)
A wrong dashboard misleads a meeting; a wrong agent silently makes thousands of decisions and takes actions. The blast radius of bad data or missing policy is now operational, not informational. - Complexity
New modalities (documents, media, embeddings), new protocols (RAG variants, MCP),and new places data lives (clouds, SaaS exhaust, shared drives) multiply integration paths. Pipelines proliferate. Governance becomes a bolted-on afterthought. Cost and Data 2.0’s pattern, move, cleanse, harmonize, store; later add semantics, quality, and access, cannot keep up. You can “agentify” each step, but the math doesn’t change. You’ve just automated a hairball.

The Data 3.0 thesis
When complexity becomes unmanageable, proven engineering practice across a wide variety of problem domains is to:
- Encapsulate the complexity into units with clear boundaries
- Provide stable interfaces to those units
- Automate orchestration so humans or hand-tooling aren’t the control plane
Data 3.0 applies that playbook to data itself, introducing autonomous data products.

Autonomous data products (ADPs)
Think of an autonomous data product as a running application for a specific domain concept (e.g., cross-channel customer feedback). Each ADP:
- Encapsulates semantics, code, data, and computational policy (quality, integrity, compliance) as one unit—at build time and runtime.
- Ingests multimodal inputs (events, tables, APIs, docs) and serves multimodal outputs (tables, files, embeddings, MCP tools) from the same semantic model.
- Self-orchestrates dependencies and reacts to changes (upstream schema shift, new tool protocol, policy update) without central pipeline choreography.
- Publishes a globally addressable API/URL for discovery, access, lineage, and control, so agents can find and use it by intent, not by spelunking storage paths.
- Adapts to heterogeneous stacks via drivers (keep your warehouses, lakes, compute engines, and security infra). No re-platforming, no one-stack mandate.

A concrete picture
Imagine a “Customer Feedback” ADP downstream of two upstream ADPs: one for PDF notes and attachments, another for public product reviews. Each upstream unit enforces integrity and policy before publishing. The Customer Feedback ADP:
- Aggregates and re-checks quality/compliance
- Exposes the same domain concept as SQL (analyst use), embeddings (RAG), documents (audit), and an MCP tool (agents)
- Emits rich lineage that spans stacks and clouds
- Enforces access control at the product boundary
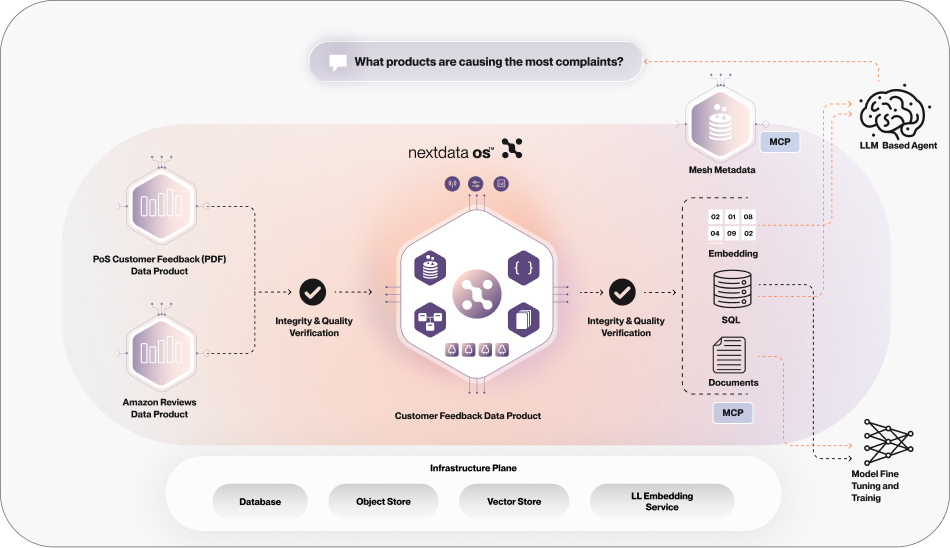
Without ADPs, you’d build (and babysit) separate pipelines per modality, glue on lineage, and hope your catalog reflects reality. With ADPs, one autonomous unit handles ingestion, transformation, semantics, policy, and service, continuously.
Data 3.0 vs Data 2.0

The shift from Data 2.0 to Data 3.0 marks a fundamental change in how we think about data itself. Data 2.0 was built for humans — passive, centralized, pipeline-driven, and optimized for dashboards that informed decisions long after the fact. Data 3.0 is built for AI, decentralized, semantic-first, and continuously operational. Instead of brittle, human-managed pipelines, we now have autonomous data products: self-describing, self-orchestrating, and self-governing building blocks that safely expose data at machine speed. It’s the abstraction that allows enterprises to move from manual insight creation to real-time AI impact, where data can be safely found, trusted, and acted on by both humans and agents.Here are the specific shifts:

The architectural moves that make it real
- Encapsulation as a container Package semantics, code, data contracts, and policies into a versioned, deployable unit. Treat “data + meaning + rules” as one artifact.
- A runtime brain per product Each product runs a lightweight controller (think micro-kernel) that evaluates policy, tracks dependencies, emits lineage, and exposes APIs. No central conductor.
- Driver-based interop Products load drivers for storage, compute, security, and protocols at runtime. Your stacks remain; products adapt.
- Multimodal by design Model the domain, not the output. Serve the same knowledge as SQL, embeddings, documents, or tools—without duplicative pipelines.
- API-native discovery Each product publishes machine-readable capabilities (what questions it answers, what tools it provides). Agents select the right product by intent, not by location.
Why “domain-first” isn’t optional
With LLMs and agents, more context isn’t always better. Dumping a lake into a prompt bloats tokens and invites hallucination. Domain-scoped context—served through autonomous products—keeps agents precise, cheap, and auditable. That requires semantics at the source and governance in the flow, not after deployment.
What changes for teams
- Platform moves from building shared pipelines to operating a fleet of autonomous products (templates, drivers, policy libraries, SLOs).
- Domain builders own their own data supply chain where knowledge lives; they ship products, not tables.
- Security/compliance codify rules once; the runtime enforces them everywhere.
- AI teams consume trustworthy, scoped context via stable APIs and tools—no bespoke wiring per use case.
Bending the data productivity curve
Across hundreds of enterprise projects, the pattern is consistent: ~6 months from new source to “first useful thing." The more data ambitious they become, the slower their cycles of data innovation. They reach a premature data productivity plateau.
Data 3.0 bends the data productivity curve by collapsing integration → processing → governance → service into a single autonomous unit that’s born semantic, governed, and API-ready.
This isn’t a new buzzword for the same stack. It’s a new unit of work for data in an AI-native enterprise.

Getting practical
If you’re evaluating where to start:
- Pick one domain with clear business questions and mixed modalities (e.g., customer feedback, claims, parts inventory).
- Define the semantic contract: the questions the product answers and the policies it must uphold.
- Stand up one autonomous data product that ingests multimodal inputs and serves at least two outputs (e.g., SQL + MCP tool) with built-in lineage and policy.
- Measure time-to-first-use, token cost for AI tasks, and incident/blast-radius reduction versus the pipeline approach.
- Template it. The second and third products should feel like copy-paste with domain tweaks.
Data 3.0 isn’t about ripping out your lakehouse or warehouse. It’s about putting autonomous products above them so your data finally moves at the speed of your AI.
If you'd like to learn more, you can check out my talk on Data 3.0 below, or register for our upcoming webinar, 8:30 AM Pacific on October 3Oth.
.jpg)

.jpg)
.png)




