
Autonomous Data Products
How to build an autonomous data product – fast
For too long, building production-ready data products has meant duct-taping together orchestration, quality checks, metadata documentation, access control, and infrastructure provisioning — often across half a dozen tools and involving multiple hand-offs between teams.
But what if publishing a robust, policy-aware, AI-ready data product could be as simple as writing a few declarations?
In this video, Zhamak walks through exactly what it looks like to build autonomous data products using Nextdata OS.
Watch the full demo here: How to Build Autonomous Data Products
Or Click here for your own custom demo now.
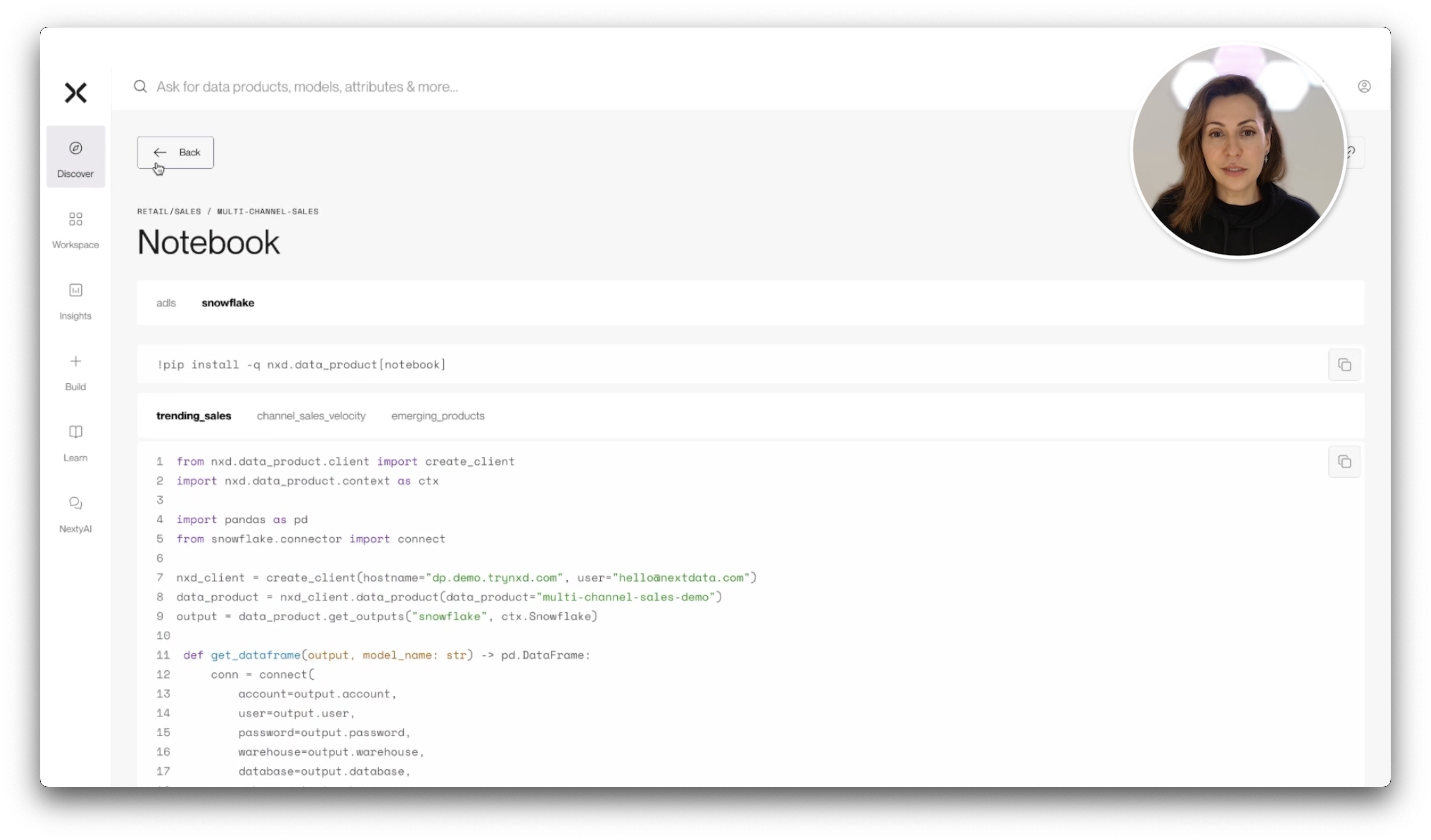
Stay in Your Flow
Whether you're working in a Jupyter notebook, a VS Code IDE, or pushing code to Git, Nextdata OS is designed to meet you where you are. It augments your existing workflow—not replaces it.
In the video, Zhamak walks through a real-world example: a team writing Python logic to identify trending products in multi-channel sales. From there, the magic begins.
From Code to Autonomous Data Product in Minutes
To create a living, autonomous data product, all you need to do is:
Declare the product: name, description, and purpose
Specify inputs: including schema expectations and failure behavior
Define outputs: including data guarantees
Add controls: like access policies and data retention
That’s it. You can use Python, YAML, or SQL—or even generate the spec from your existing data assets using our AI assistant, Nexty.
Nextdata OS encapsulates not just transforms and policies, but also semantic models and contracts. Schemas are compatible with Apache Arrow for maximum interoperability, and Promises and expectations, compatible with the tools you love—Soda, Great Expectations, Monte Carlo, or plain code.
Nextdata takes care of running these validations at the right time, with no extra orchestration required.
One Spec. Full Autonomy.
Once you submit your data product spec, Nextdata OS handles everything:
Provisions infrastructure (Snowflake, Databricks, ADLS, etc.)
Monitors data inputs for changes
Runs transformations, validations, and logic
Protects access and enforces contracts
Surfaces real-time health and performance metrics
No manual orchestration. No waiting on infra. No more duct tape.
One URL. Everything You Need.
Every autonomous data product gets a single web-addressable URL. This link includes:
- Metadata and discovery
- Access control
- Output data
- Quality metrics
- Operational health
Share it with a teammate. Plug it into an AI agent. Call it from code. If they have appropriate access, they’re good to go.
Watch the Demo
Want to see this in action? Here’s how to build an autonomous data product from scratch showing you what’s possible when your data infrastructure finally works with you, not against you.
Watch the full demo here: How to Build Autonomous Data Products
Or Click here for your own custom demo now.
.jpg)

.jpg)
.png)




