
.png)
Data for AI
Domain-Centric GenAI: Serving Smart Context with Autonomous Data Products
Enterprise teams moving LLMs from prototype to production hit two blockers. The first is the AI data gap: how do you safely connect RAG applications, chatbots, and agents to company data? Teams must establish secure, reliable data access before systems become operational.
Once teams solve the AI data gap, they typically swing to the opposite extreme: context overload. When data sources become accessible, teams expose everything to their LLMs and agents: entire data lakes, hundreds of tools, generic prompts applied across vastly different use cases. The system drowns in unfiltered information.
The consequences pile up. Token costs explode. Models hallucinate by extrapolating from unspecific context. Tool calling becomes unreliable because the LLM cannot determine what's relevant.
GenAI isn't magic. It's math, compute, and context. When context becomes too broad, systems fail.
Domain-centric GenAI bypasses context overload by giving AI exactly what it needs for each domain. Finance maintains its own context, vocabulary, and rules. Engineering maintains theirs. Marketing maintains theirs. Each operates within its bounded context, preventing the semantic confusion and attention dilution that plague universal systems.
Where domain-centric design comes from
Domain-centric GenAI builds on domain-driven design, a principle Eric Evans introduced in 2003. Instead of starting with technology and forcing business domains to conform, it inverts the relationship. Business domains drive technical architecture.
The core concept is bounded context: clear boundaries within which a domain model applies. A bounded context defines what belongs to a domain (its data, logic, and vocabulary) and what remains outside. These boundaries prevent domains from interfering with each other while allowing controlled interactions.
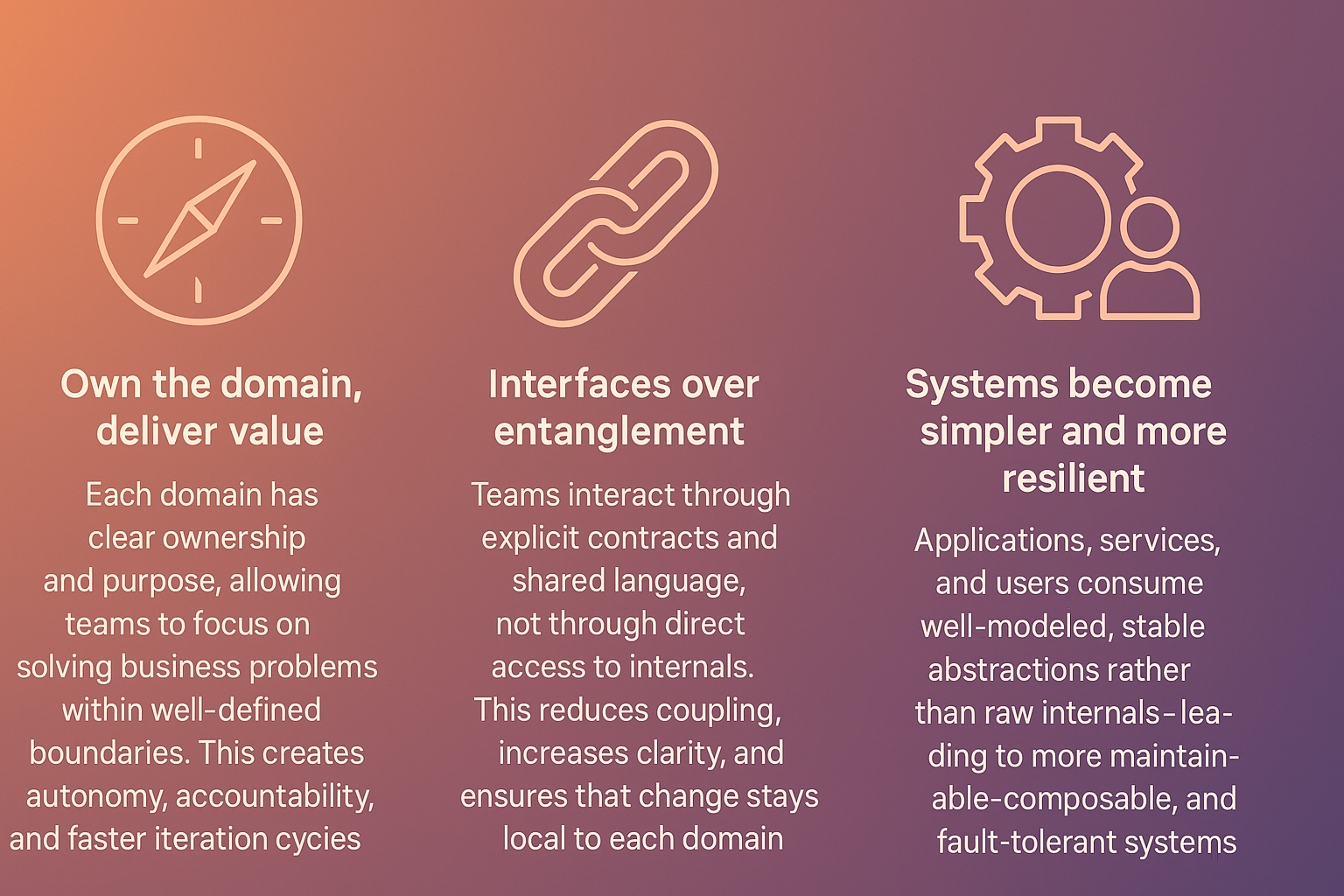
The approach also uses four data mesh principles:
- Domain-oriented decentralized data ownership: each business domain owns and manages its data, rather than centralizing everything in one team or platform.
- Data as a product: data gets treated as a product with clear ownership, quality guarantees, and user experience considerations.
- Self-serve data infrastructure: teams independently create and manage their data products without centralized data engineering bottlenecks.
- Federated computational governance: governance policies apply globally while teams operate autonomously within those guardrails.
This architecture provides the foundation for domain-centric GenAI. When each business domain owns its data products, GenAI systems scope their context to the relevant domain

The GenAI challenge: focus, not flood
When teams solve data connectivity, they often swing to the opposite extreme: exposing everything. Imagine a single MCP endpoint in front of Snowflake doing text-to-SQL, with your entire data lake exposed to agents. Or hundreds of tools available simultaneously to a single agent.
Think about how you'd work with a human assistant. If you need a legal assistant to find a clause in a contract, you provide that contract and associated documents. You don't hand them vacation photos, Slack threads, and unrelated PDFs. Those would distract them. The same principle applies to LLMs and agents, which will consume all available data whether relevant or not.
The challenge is providing relevant context to the task at hand. Business domains provide natural boundaries. Marketing context for marketing tasks. Finance context for finance tasks. Engineering context for engineering tasks.
1. Context overload
The attention mechanism explains why more context hurts performance. Think of attention like a spotlight with fixed brightness. Point it at one thing, and it stays focused. Try to illuminate everything at once, and each item receives less light.
Every token in the context window competes for finite attention resources. Your important domain-specific document competes equally with irrelevant boilerplate, accumulated conversation history, and system prompts. The model cannot distinguish semantically important information from noise.
The counterintuitive finding: more data often reduces output quality.
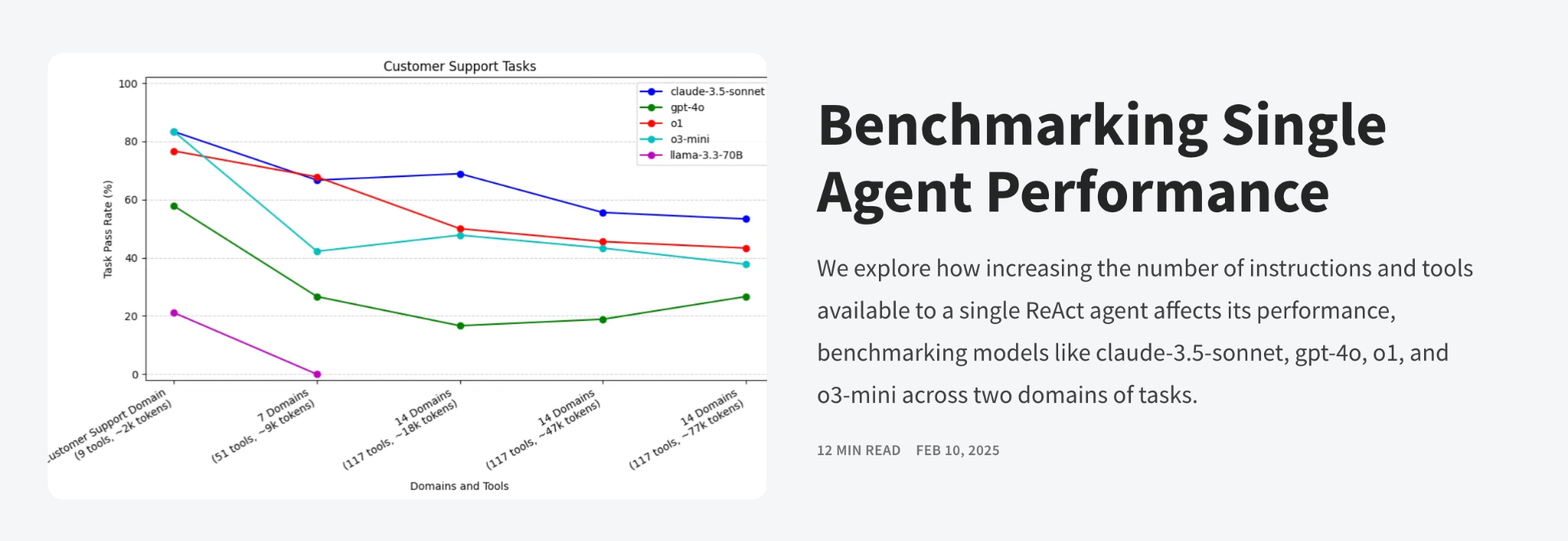
2. Token economics
Unlike traditional software, LLMs charge per token for both input and output. Costs scale with data volume.
Input Tokens: Every piece of context you send costs money. A typical RAG system might use 10,000+ input tokens per query.
Output Tokens: Every word the model generates costs money, typically 3-5x more than input tokens.
Doubling context length often triples or quadruples costs. Longer contexts produce longer responses, increasing both input and output costs simultaneously.
Hidden context accumulation makes this worse. Chat applications accumulate conversation history. RAG systems retrieve more documents than necessary. System prompts add overhead to every request. Error handling and retry logic multiply costs unexpectedly.
3. RAG retrieval failures
RAG systems promise to find the most relevant information. Without domain boundaries, retrieval suffers from cross-domain contamination. This is the most significant hidden problem in enterprise RAG systems.
The Vocabulary Overlap Problem
The same terms mean different things across domains. Take "pipeline." In sales, it's deal progression. In engineering, it's data transformation. In manufacturing, it's production lines. "Security" could mean cybersecurity, financial instruments, or physical protocols.
Embeddings trained on general data cannot distinguish these domain-specific meanings. "Customer retention in SaaS" and "customer retention in retail" appear semantically similar even though the contexts, metrics, and strategies differ completely. Technical terms get conflated: IT's "deployment" versus Marketing's "campaign deployment." Acronyms multiply the confusion: "API" could mean Application Programming Interface, Annual Percentage Increase, or Active Pharmaceutical Ingredient.
Domain Boundary Breakdown
This problem shows up when documents from different domains compete in the same vector space. HR documents about "scaling teams" contaminate engineering documents about "scaling systems." Financial "models" compete with ML "models" in search results. Semantic similarity stays high while business context differs completely.
The fix: scope retrieval to specific domains. Finance docs serve finance tasks. Engineering tickets answer engineering questions. The HR domain never sees engineering tickets. Finance queries never pull marketing materials. Each domain stays in its lane, and retrieval relevance improves because the model only searches within appropriate boundaries.
4. Tool overload
LLMs with tools are like kids in a candy store: they'll try everything if you let them. More tools does not improve performance. Overexposure leads to hallucinated tool calls and tangled reasoning.
When you expose every tool to every task, decision-making becomes diluted. The LLM attempts inappropriate tools, makes incorrect calls, or chains tools in nonsensical sequences.
These four challenges share a common root cause: lack of boundaries. Solving them requires infrastructure that enforces domain boundaries by design.

Autonomous data products
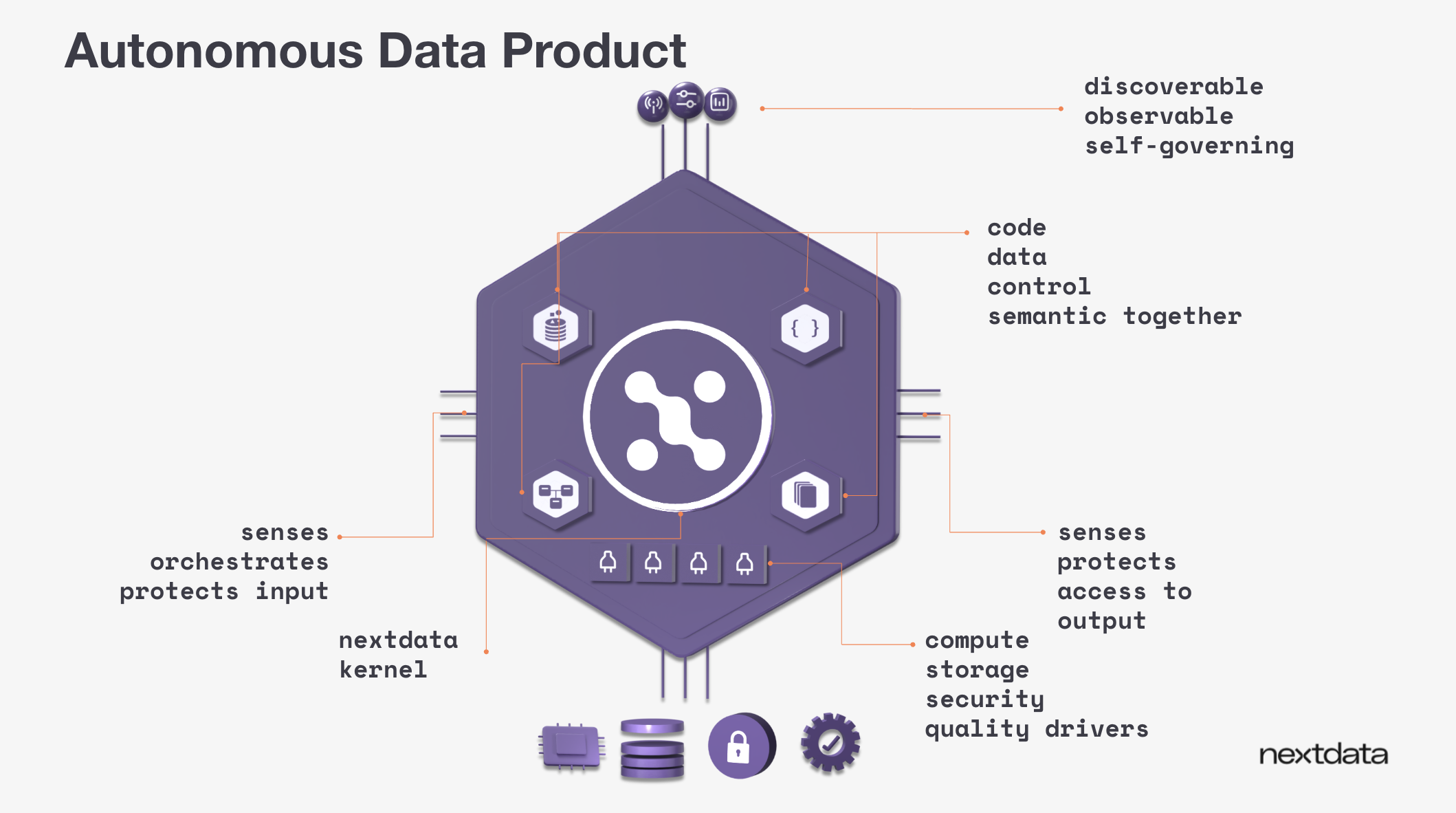
Autonomous data products operate as running services with their own lifecycle, unique URL, and API. They manage the complete journey from input sensing through validation and transformation to serving outputs. When you share a data product's URL with a coworker, they access metadata, request APIs, quality guarantees, and the data itself.
The six-stage lifecycle
Autonomous data products follow a lifecycle that ensures quality, prevents compute waste, and maintains coherence:
Sense: The data product monitors inputs and determines when processing makes sense. Unlike traditional Spark jobs that run hourly regardless of new data, autonomous data products adapt to actual update patterns. Amazon reviews might arrive minute-by-minute while point-of-sale feedback arrives weekly. The system processes when updates provide value.
Check expectations: The data product validates input quality before processing. Does the data have required fields? Is it fresh enough? Do values fall within expected ranges? If expectations fail, processing stops before wasting compute.
Orchestrate transform: The data product runs transformation logic through existing compute platforms (Python scripts, Databricks Spark, Snowflake queries). Data remains in underlying storage while the data product coordinates operations and maintains a coherent view across technologies.
Validate promises: After transformation, the data product validates outputs against quality guarantees: freshness thresholds, completeness requirements, schema contracts. If validation fails, outputs get blocked.
Promote: Once validation succeeds, the data product makes outputs available. This creates a clear boundary between data ready for consumption and data still being processed.
Serve multi-modal outputs: The data product provides its semantic model through multiple formats: embeddings for RAG applications, SQL tables for BI tools, file formats for ML training, and API functions for agent access.
Serving multiple output formats from a single lifecycle solves a coherence problem that commonly occurs when separate pipelines produce different output formats. When one pipeline creates vector embeddings and another computes SQL output, they can fall out of sync. A single failure in one pipeline, or simply different runtimes between them, means consumers querying both formats simultaneously receive inconsistent results. Debugging these mismatches becomes difficult because the root cause spans multiple systems. By orchestrating all outputs through a single data product lifecycle, all formats stay synchronized and represent the same underlying state.
Inspecting a data product
When evaluating whether to use a data product, consumers inspect several layers of information. Semantic data models show what attributes the data product exposes and how those attributes relate to concepts in other data products. A product ID field can declare that it maps to the same concept in sales analytics, inventory management, and customer feedback. These semantic relationships function like foreign keys at the business concept level, letting consumers see how to join information across data products without guessing.
Health indicators signal trustworthiness: when the data product last updated, whether it is currently running, and its compliance rate against promised quality thresholds. A data product updated five minutes ago with 100% promise compliance signals reliability. One with failing quality checks or no recent runs signals risk.
Usage patterns offer additional validation. A data product accessed frequently by multiple downstream consumers carries implicit trust. A data product with no consumers despite existing for months raises questions about its value. These indicators transform trust from subjective judgment into observable properties.
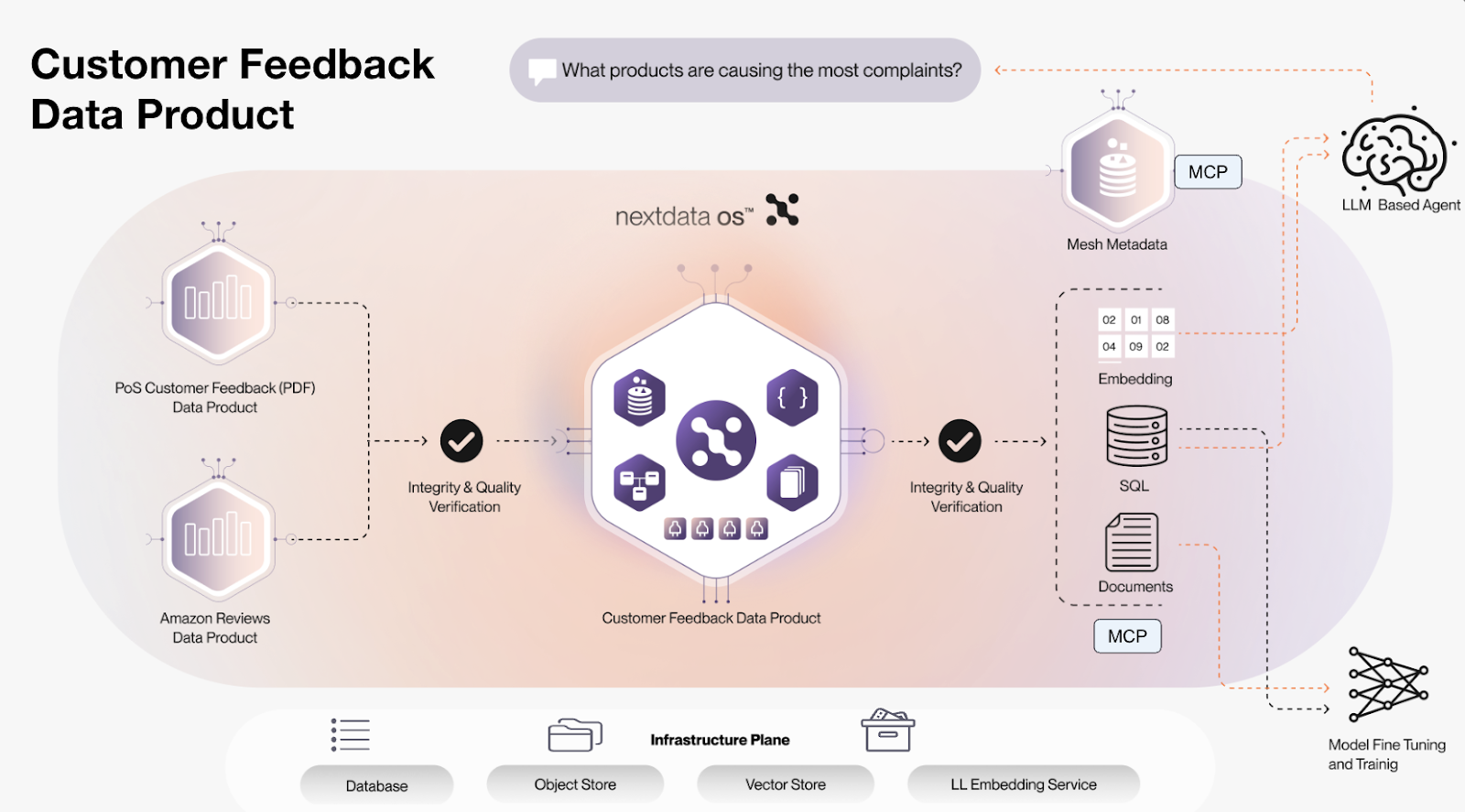
The ADP lifecycle provides three capabilities that eliminate context overload. First, standardized interfaces let LLMs and agents interact through consistent APIs regardless of underlying technology. Code that worked against a DuckDB prototype works against production Snowflake without rewrites. Second, domain ownership allows finance teams to build data products for financial metrics while engineering teams build for system performance. Domain expertise drives design. Third, the expectations and promises framework ensures consumers know what they can rely on. Data passes both input validation and output quality checks before becoming accessible.
These capabilities give us the foundation. But how do you architect a system that uses them? That's where the three pillars come in.
Three pillars of domain-centric GenAI
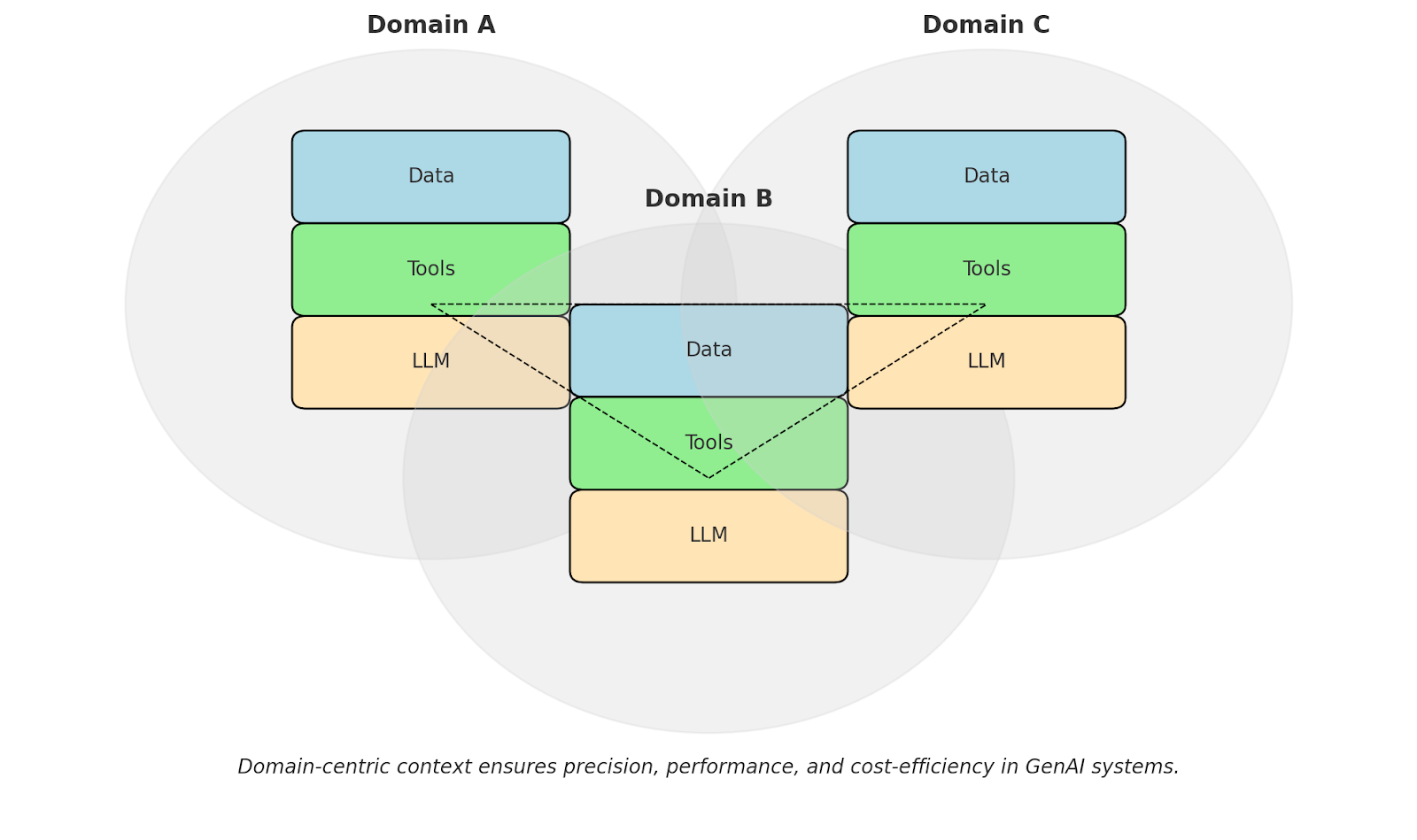
Domain-centric design tackles context overload via three coordinated pillars. Each pillar scopes a different dimension of what LLMs and agents can access: what data they see, what tools they can invoke, and which models process their queries.
1. Domain-driven data
Domain-driven data separates information by business context before it enters the retrieval system. Take vector databases as an example: rather than one massive vector database, you create domain-specific vector stores.
How it works
When a query arrives, the system follows this flow:
Domain identification: Determine which domain the query belongs to based on intent and context
Scoped retrieval: Search only within that domain's vector store
Focused context: Return only domain-relevant documents to the LLM
This approach builds on MeshRAG. The system first checks metadata about available data products, then connects only to relevant ones and retrieves their embeddings. This two-step approach (selecting data products first, then retrieving from their outputs) fine-tunes results and achieves more relevant context.
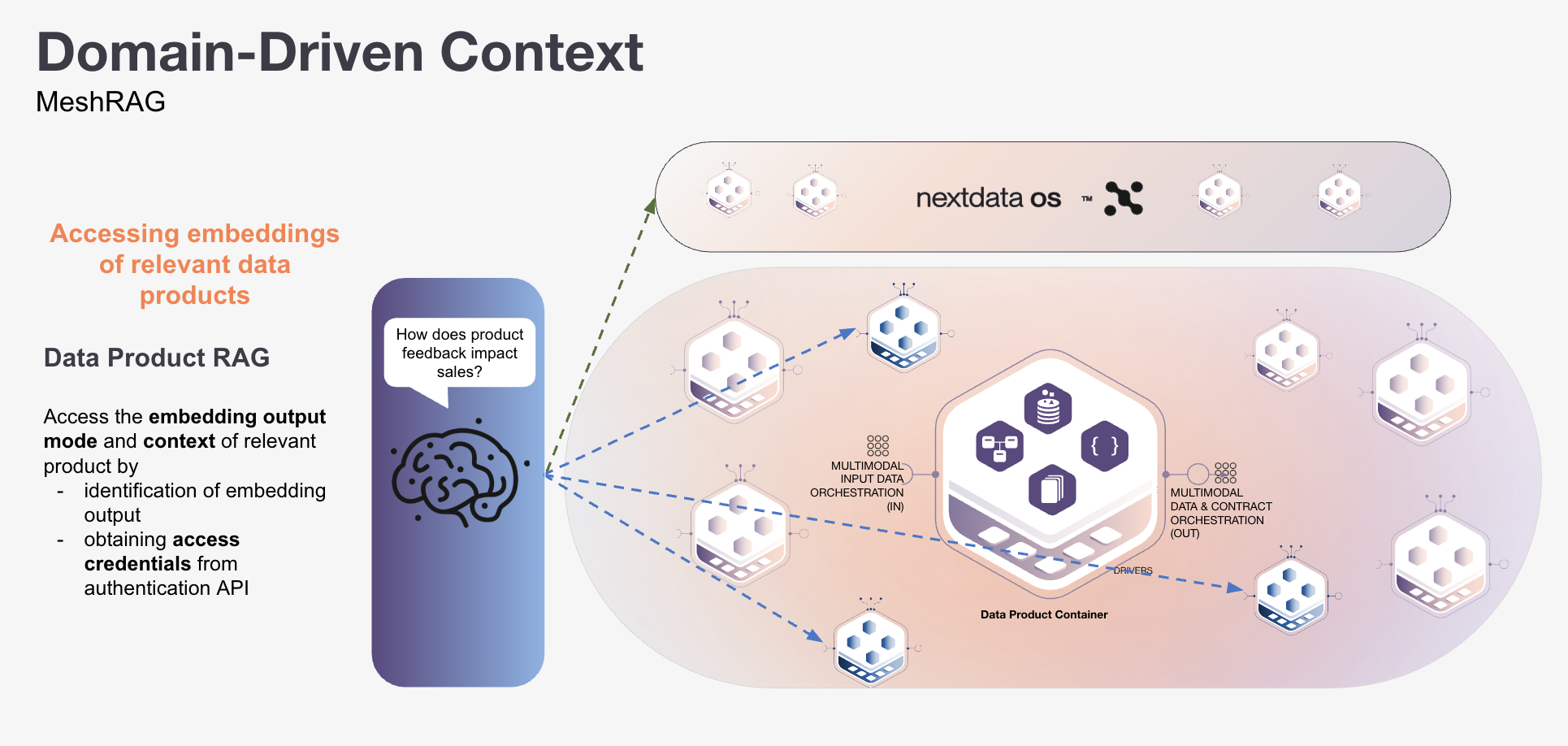
Consider the query "how does product feedback impact sales?" The system first evaluates what data products exist and which ones are relevant. Customer feedback and sales analytics data products match. Banking data products, wholesale operations, and HR resources do not enter the search space at all. Retrieval happens within appropriate boundaries because the system selected the right data products before any vector search occurred.
2. Domain-aware tools
LLMs can be extended with tools (APIs, calculators, DB access, etc.). Exposing every tool to every task dilutes decision-making. A domain-centric approach restricts tool exposure based on what the task requires.
How it works
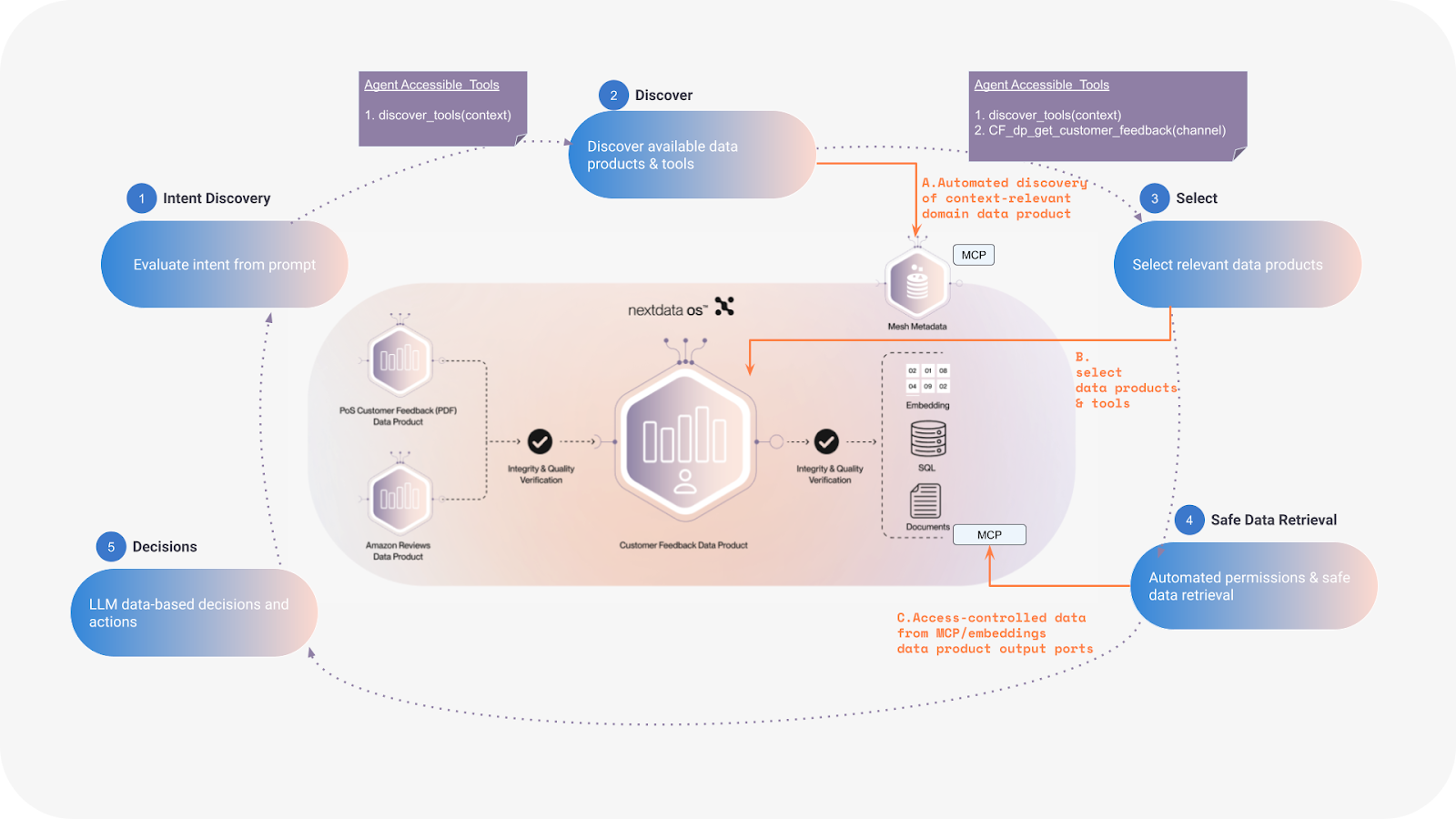
Rather than exposing all tools upfront, domain-aware routing follows a lifecycle that progressively discovers and scopes capabilities:
Intent discovery: The agent evaluates the input to determine intent and context. At this stage, it only has access to one tool: discover_tools. This prevents the agent from solving problems before understanding what capabilities it needs.
Dynamic discovery: The agent invokes discover_tools with specific context. The system checks what metadata is available, what data products exist, and what makes sense for that context. Based on this analysis, relevant tools become available.
Selective access: Only relevant tools become available. An HR query about benefits never sees engineering deployment tools. A finance query about quarterly reports never sees customer support ticketing systems. The decision space contracts from thousands of tools to 5-10 relevant capabilities.
Safe data retrieval: The agent selects and invokes tools from its discovered list. Each request validates against the data product's control policies, checking both permission and quality state.
Decisions: With retrieved data, the agent continues reasoning and generates responses. If additional tools are needed, it can invoke discover_tools again with updated context.
This transforms the "candy store" problem into guided discovery. With thousands of tools potentially available, progressive discovery ensures you offer only a small, relevant subset at any time. The result: faster runtimes, more specific results, and fewer external calls.
Domain teams define tools
Domain teams decide which tools their data products expose. Instead of handing an LLM a generic text-to-SQL interface and the full database, data product owners define the questions their product answers well and build focused API functions.
This brings domain expertise into the workflow. The team that owns customer feedback data knows which queries matter, so they create tools like get_feedback_by_channel, analyze_sentiment_trends, or correlate_feedback_with_sales. When an LLM calls these, it gets clean results shaped by people who understand the data.
If you expose a full warehouse through generic SQL, the LLM has to guess at schemas, joins, logic, and business rules. Errors rise. Performance slows. Results skip important context. Letting domain teams define tool interfaces turns data access from "here's everything, figure it out" into "here are the questions we answer well, with our expertise built in."
3. Domain-specific models
A one-size-fits-all model often underperforms in specialized contexts. Asking the same model to draft a B2B sales email and analyze a quarterly financial risk report reveals performance gaps. The vocabulary, tone, and reasoning patterns differ across domains.
How it works
Different domains speak different languages. Your models should too. The finance domain needs different base LLMs, or at least different fine-tuned LLMs with different system prompts. Each domain has different requirements.
This specialization extends beyond model selection. Domain-specific LLMs become domain-scoped resources. A finance LLM might have prompts containing semi-sensitive data, so you wouldn't expose that LLM to everyone in the organization. The LLM itself becomes a resource scoped and safeguarded by domain.
The approach ranges from foundational model selection (choosing models that vary in performance for different tasks) to fine-tuning and custom system prompts tailored to domain needs.
The three pillars work together in practice. Here's how they combine in a real architecture.
Example: A multi-domain GenAI assistant
Consider a retail organization deploying GenAI across multiple business domains: sales analytics, wholesale operations, product management, and financial analysis. Each domain maintains its own focused stack.
Domain structure
The organization structures domains hierarchically. Retail serves as the high-level domain, with subdomains including sales, wholesale, and product. Each domain contains multiple data products: discrete, autonomous units managing their own lifecycle.
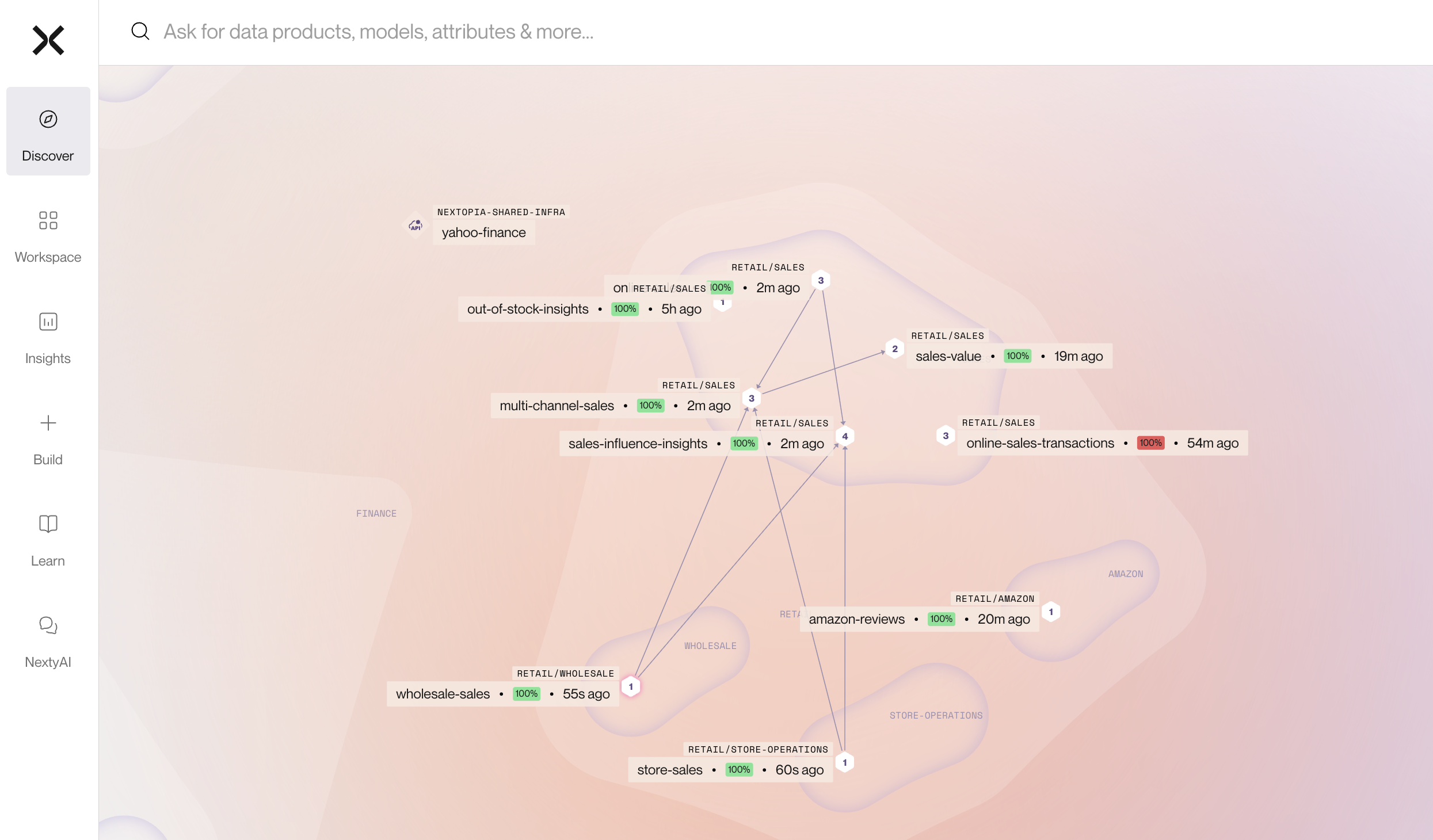
Data products connect through clear lineage. A Sales Influence Insights data product consumes from an Online Sales data product, which consumes from raw sources like Azure Data Lake Storage. This creates transparent dependency chains while maintaining domain boundaries.
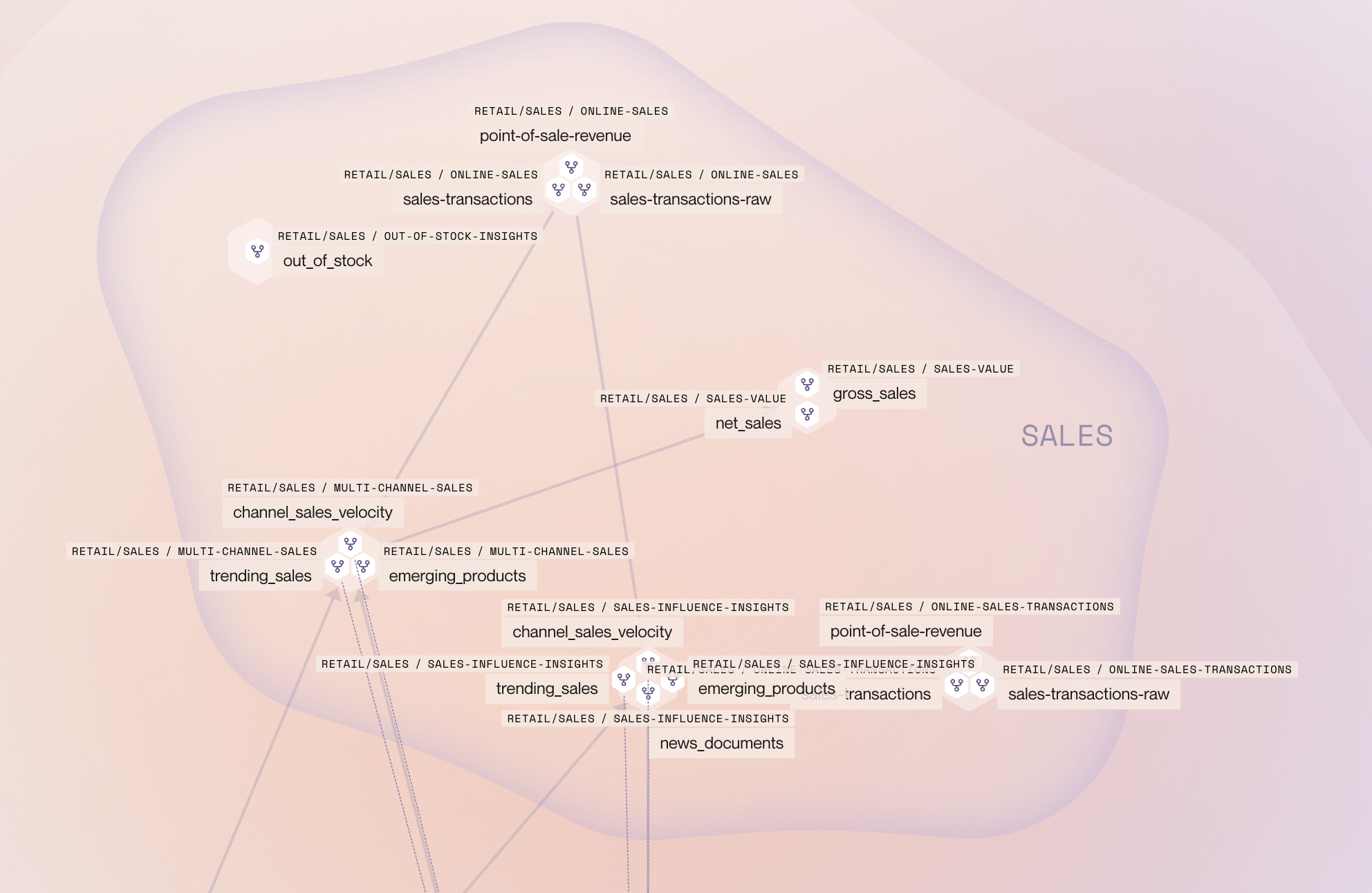
Domain-specific configuration
Each domain configures its own data products, tools, and access patterns:
Sales Analytics domain: Contains data products for multi-channel sales analysis, social media correlation, and customer feedback impact. Tools include functions to get sales correlations with news mentions and total sales by channel.
Product domain: Maintains product information, specifications, and catalog data separate from sales operations.
Wholesale domain: Operates independently with its own sales data and analytics, distinct from retail channels.
Financial Analysis domain: Includes data products for banking, deposit rates, and financial metrics, separate from operational sales data.
Progressive tool discovery in action
When an agent connects to the entire mesh, it starts with access only to high-level mesh APIs: tools to discover data products and set filters based on context.
For a query about sales and feedback, the system filters tools dynamically. Instead of exposing all tools across banking, wholesale, and product domains, the agent sees only tools relevant to sales analytics and customer feedback. Banking tools remain hidden. This reduces the decision space for the LLM.
Routing happens automatically based on query context.
Technical implementation
Each data product operates as a running service with its own lifecycle. It senses when new input arrives, checks quality against expectations, runs transformations, validates outputs against promises, and only then promotes data for consumption.
Data products maintain coherence across multiple output formats. A single customer feedback data product can serve embeddings for RAG, SQL tables in Snowflake for analysis, and files for model training. One lifecycle keeps outputs synchronized.
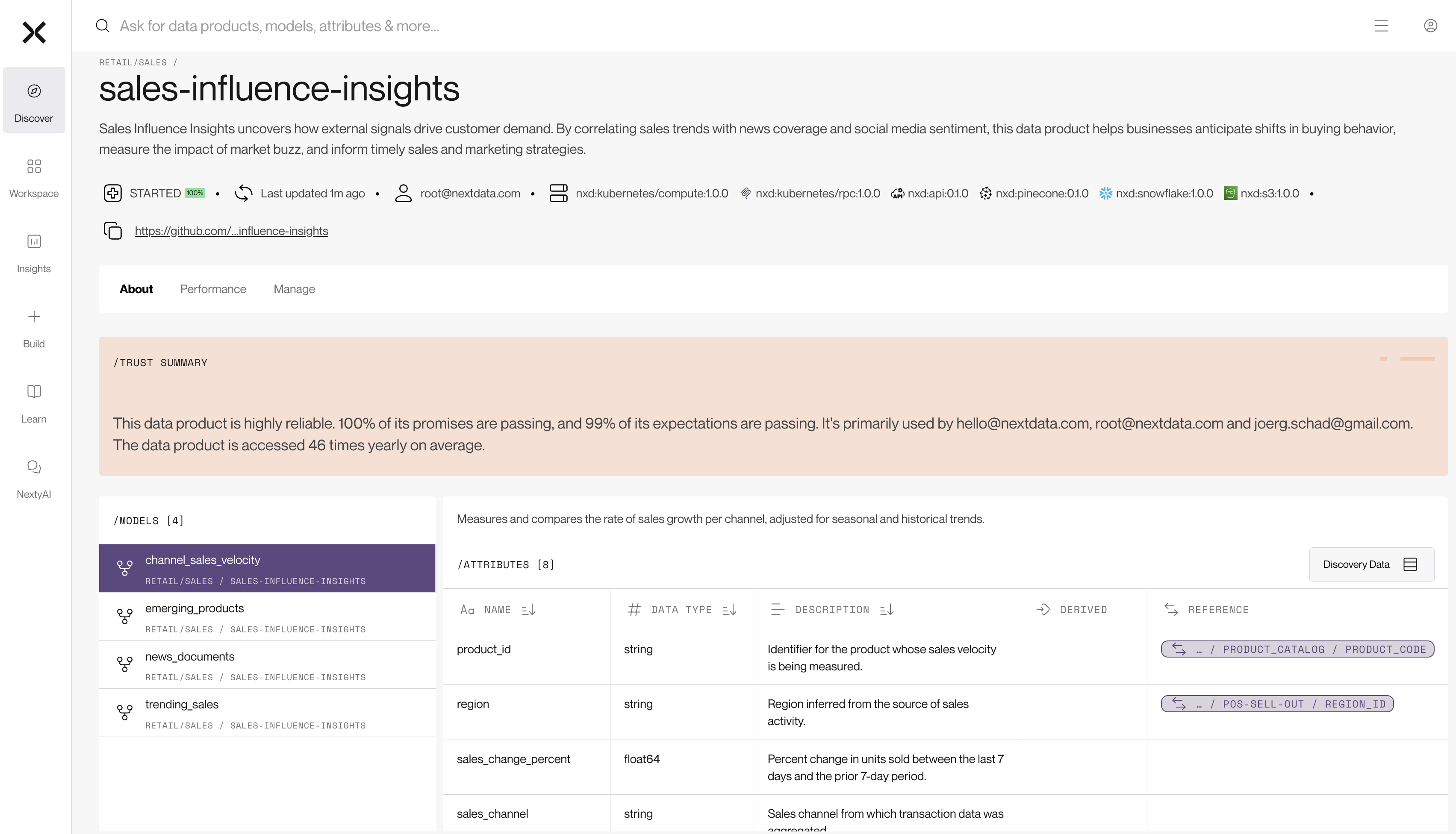
The multi-modal aspect matters for GenAI consumption. Rather than building separate pipelines for each pattern, autonomous data products provide standardized access. They define specific tools representing questions they answer well, making it easier for LLMs to access data as intended.
Summarizing the benefits of domain-centric GenAI
Domain-centric architecture delivers measurable improvements across multiple dimensions:
Improved accuracy: Less noise means better output. Scoping data to relevant domains gives models focused context that eliminates cross-domain contamination. When finance queries only access finance data, retrieval relevance improves.
Lower inference cost: Fewer tokens, fewer tools, less waste. Domain-scoped context windows reduce token consumption. Progressive tool discovery minimizes unnecessary API calls, cutting latency and cost.
Stronger governance: Domain-scoped data and tools make compliance easier. The system enforces domain-specific access rules while maintaining visibility across the mesh. Platform owners see which data products provide value. Access patterns stay traceable even when consumption happens through underlying infrastructure.
Higher confidence: Users trust GenAI more when systems stay focused and explainable. Domain boundaries create natural quality checkpoints. Each data product makes explicit promises about quality, validated before consumers see outputs.
Operational efficiency: Standardized interfaces help teams move from prototype to production. Many AI projects fail at exactly this bridge. Teams build a prototype against DuckDB, then need to switch to Snowflake for production data. Without standards, they would have to rewrite everything from scratch. Autonomous data products bridge that gap by remaining technology-agnostic while orchestrating across compute and storage services.
Cross-technology visibility: Unlike technology-first approaches requiring separate usage checks in Snowflake, Databricks, and elsewhere, domain-centric architecture provides a global view. Platform owners see what data matters across technologies, from a domain value perspective.

Conclusion
Domain-centric GenAI changes how organizations build scalable GenAI systems. The approach rests on three concepts that prevent context overload, cost explosion, and accuracy problems.
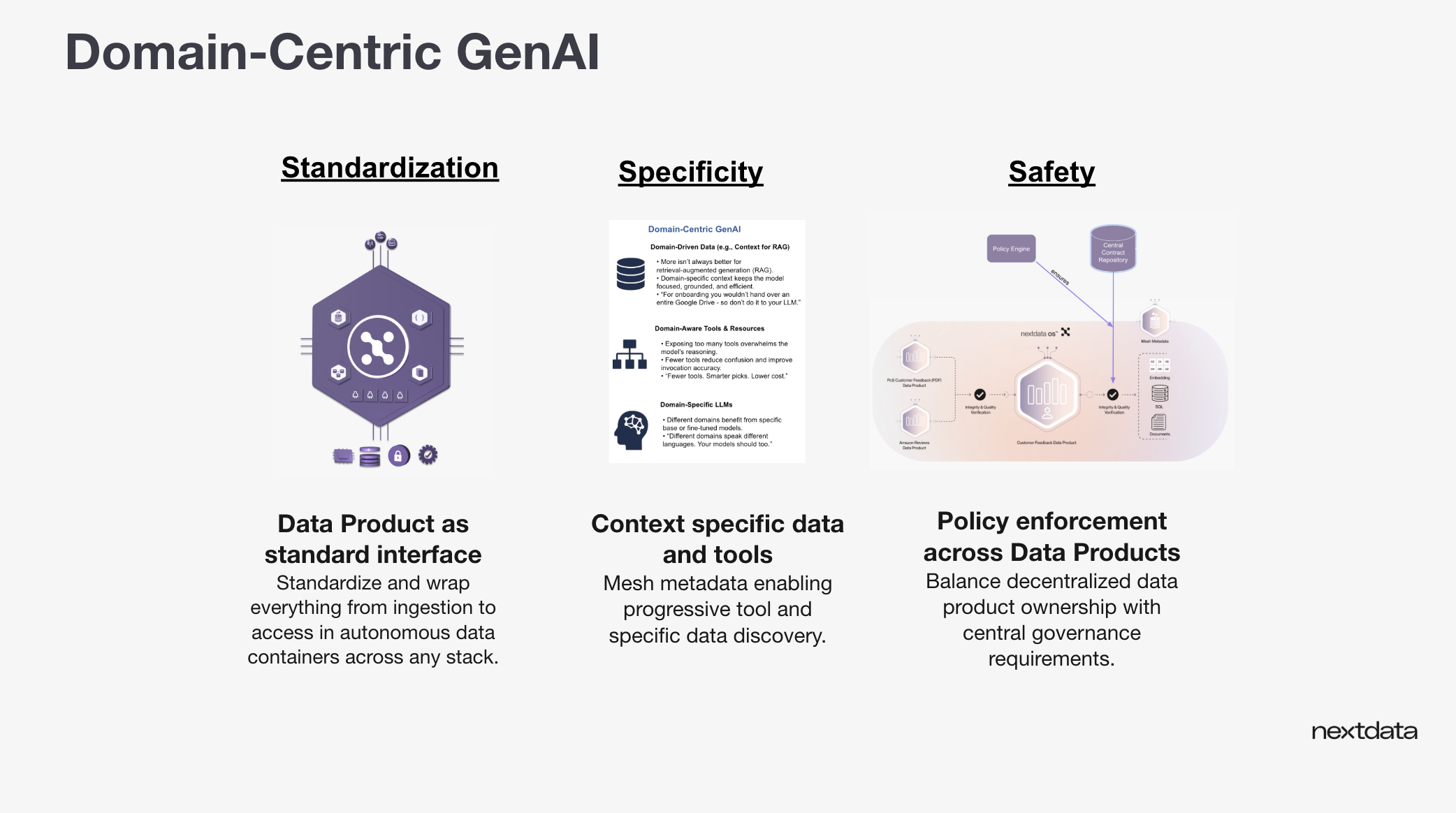
Standardization: Establish a standard interface to your data. Many AI projects fail at the bridge from prototype to production because they lack this foundation. Without standards, teams rewrite everything when moving to production. Autonomous data products provide this interface, remaining technology-agnostic while orchestrating across compute and storage services.
Specificity: Make relevant data, tools, and resources available to LLMs. Nothing more. This drives every pillar. Domain-driven data keeps retrieval focused. Progressive tool discovery prevents dilution. Domain-specific models speak the right language. The goal is precision.
Safety: Ensure data access happens safely. This means more than access control. Computational policies prevent PII exposure through vector outputs. Data products validate quality at input and output stages. Governance becomes integral to the architecture, enabling teams to move quickly while maintaining compliance.
Domain-centric GenAI provides exactly what AI needs, when it needs it, scoped to the domain and task at hand.
.jpg)

.jpg)





