
.jpg)
Autonomous Data Products
Data 3.0: The structural shift from schema-first to semantic-first
Thank you to everyone who joined our live session Nextdata Product Update: Data 3.0 - Domain-Oriented Semantic Context for AI Agents!
The move from Data 2.0 to Data 3.0 does not begin with a better prompt, a richer ontology, or another layer of metadata. It begins with structure.
“That was the focus of our recent product update: the first foundational shift in Data 3.0, from storage-centric, schema-first data processing to domain-oriented, semantic-first data processing, and how Nextdata OS autonomous data products implement it”.
A quick recap: the problems Data 3.0 addresses
For years, the modern data stack, what we call Data 2.0, has been optimized for a particular consumer: the human analyst. Data was collected, moved, cleaned, modeled, cataloged, and governed so people could interpret it through dashboards, notebooks, and applications.
That model was imperfect, but workable, because the final act of interpretation still happened in a human mind.
The next generation of systems changes that assumption.
Now the consumer is increasingly an agent. Or a copilot. Or an application expected to discover, reason about, and act on data with limited human intervention. That changes the job of the data architecture itself.
A system designed around tables, schemas, and storage locations may still be queryable. But that does not make it intelligible to an agent. And it certainly does not make it reliable.
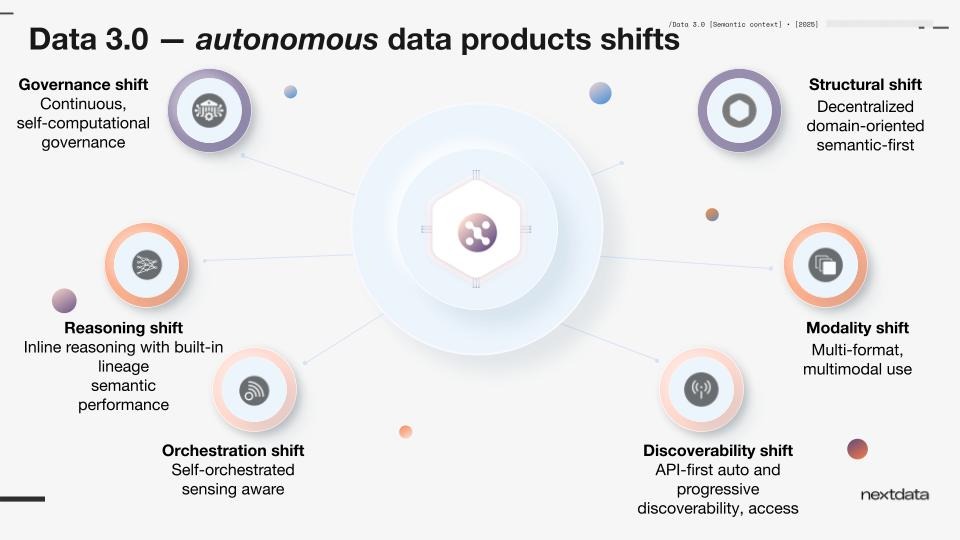
Data 3.0 addresses this through six foundational shifts: structural, modality, discoverability, orchestration, reasoning, and governance. In this webinar, we focused on the first and most foundational of those shifts.
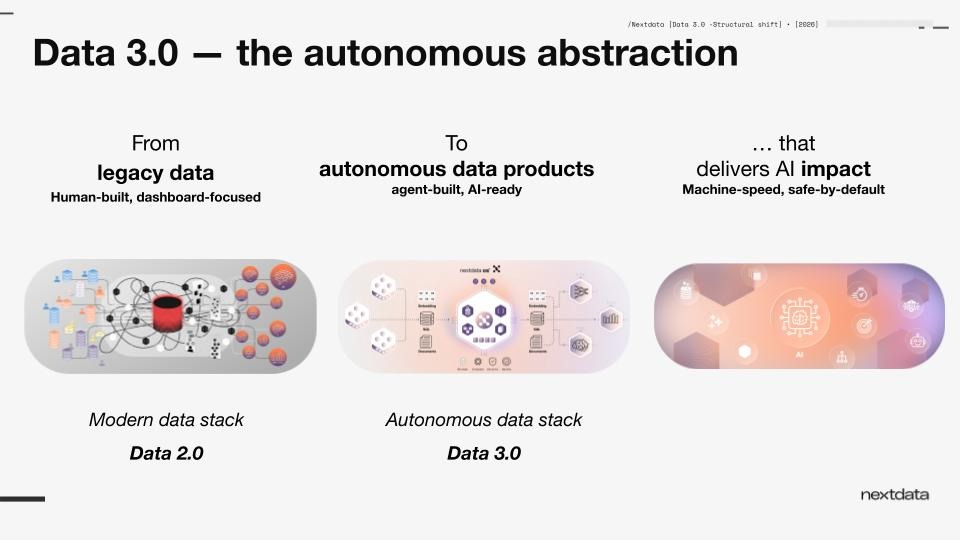
Why the first shift is structural
The first shift in Data 3.0 is structural because everything else depends on it.
If the structure of the system still treats data as raw bits to be organized after the fact, then every downstream layer is compensating for the same underlying problem. Semantics gets added later. Policies get added later. Observability gets added later. Discovery gets added later. Context gets added later.
That is the pattern of Data 2.0: a storage-centric foundation with layers of interpretation built on top.
For agents, that is not enough.
Agents do not just need access to data. They need access to ground truth expressed in business terms. They need to understand what something is, how it relates to adjacent concepts, when it should be used, whether it is healthy, how it is governed, and what its current state implies. If those things live in separate systems, or are maintained as overlays, they drift.
So the structural shift is this:
from centralized, storage-oriented, schema-first data processing to decentralized, domain-oriented, semantic-first data processing.
Not as an annotation exercise. As the architecture itself.
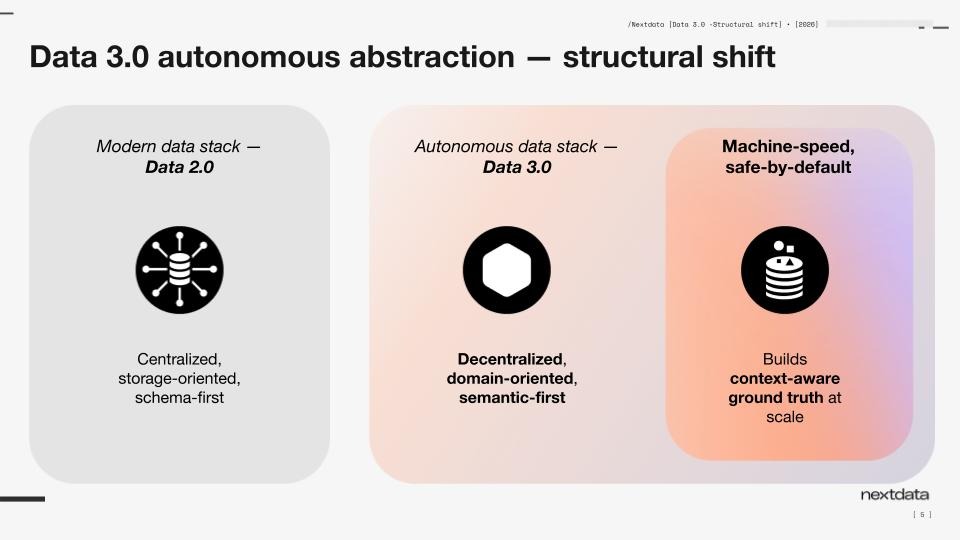
From schema context to business context
A schema can tell you column names, types, and relationships at the storage layer.
It cannot tell you, in any durable way, what the business actually means by “promotion effectiveness,” “active customer,” “clinical eligibility,” or “gross profit.” It cannot carry the living operational state of those concepts as they are produced, updated, governed, and consumed. And it does not give an agent a stable business-aligned surface on which to act.
Take something as simple as a quarterly revenue figure. Is that a calendar quarter or a fiscal quarter? When an agent interprets data without explicit semantic definition, it has to infer. And that inference — as we showed in the demo — can produce confidently wrong answers. Without the glossary term defining that Q1 runs February to April (incorporating seasonality), the agent defaulted to October–December. A small semantic gap with real business impact.
In Data 3.0, the unit is not the table. It is the autonomous data product: data and its processing behaving like an autonomous application, centered around business domains, business semantics, and business context first. Instead of producing raw data and then layering semantics and governance afterward, the autonomous data product combines production and access into one runtime. As it runs, it continuously carries and maintains context around the business concept it represents.
That context is not just descriptive. It is operational. It includes semantic meaning, yes, but also relationships, quality signals, usage patterns, policy state, and other dimensions that become available because the product itself is responsible for its own lifecycle.
This is the practical meaning of semantic-first: not that semantics exist somewhere in the estate, but that they are built into the way the product operates.
The impact of the Data 3.0 structural shift
This first shift creates the foundation for everything else in Data 3.0.
When data processing is domain-oriented and semantic-first:
Agents can discover data by business intent, not storage path.
They can reason over concepts, not just schemas.
They can use multimodal outputs aligned to the same business object.
They can inherit governance and trust signals as part of the product, not through after-market stitching.
They can interpret what is happening in the business domain itself, not just statistics about a table.
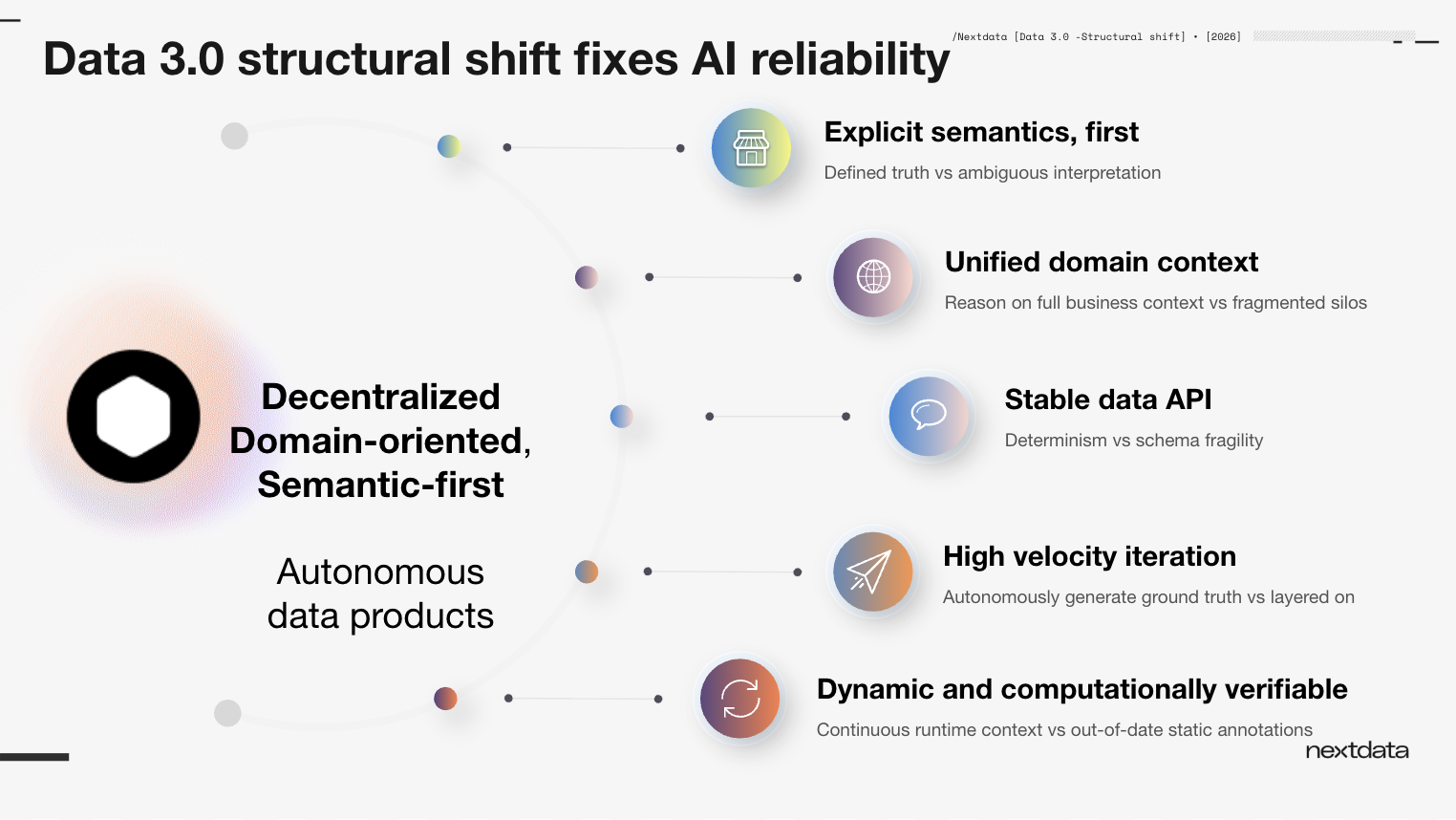
How Data 3.0 structural shift fixes AI reliability
Nextdata’s autonomous data products implement a semantic-first, domain-oriented approach to data processing, addressing five key failure modes for AI agents that arise when context is added after the fact through catalogs or context layers:
Defined truth vs. ambiguous interpretation. Explicit semantics built into the data product mean agents operate from defined ground truth, not inferred meaning.
Unified domain context vs. fragmented silos. Semantic definitions, data, functions, health signals, and policies are all bundled together and available through a single data product, not scattered across separate systems.
Stable data API vs. schema fragility. The interface for agents is not a volatile schema layer but a stable API that improves determinism in agent behavior.
High velocity iteration vs. slow layered processes. When data products autonomously generate and maintain their own context, the time from data to agent-ready action compresses from months to hours.
Dynamic and computationally verifiable vs. static annotations. Context is generated and verified at the time of production, not added as a post-hoc annotation that drifts from the data it describes.
Why catalogs and semantic layers are not enough
Most organizations already have some answer for semantics.
A catalog provides descriptions and ownership.
A glossary defines terms.
A graph captures relationships.
An observability tool tracks freshness or quality.
A governance system applies controls.
Each of those can be useful.
None changes the structure of data production itself.
As Zhamak noted in the session: you can go and annotate your data in a catalog tool. The difference is there is no reliability or trust in something annotated after the fact versus something enforced consistently in the flow of the data. When a policy runs and a data product fails because it has exposed a PII attribute without the appropriate promise protecting it, that failure happens because the running data product encapsulates its semantic, its data, and the code producing that data together — and enforces validation continuously as part of its lifecycle.
That is what enables agents to reason with higher accuracy and act with more reliability. Not because they have access to more information in the abstract, but because the structure of the system gives them a more faithful representation of business reality.
Nextdata autonomous data products: dynamic, multidimensional context in action
The webinar introduced this first shift through a product demonstration focused on dynamic, multidimensional context.
The point was simple: when the data product changes, the context available to an agent changes with it. And when context improves, the agent can do things it previously could not do, or do them more accurately, more safely, and with clearer explanation.
That is a very different story from traditional data architecture.
In the older model, context is managed independently, across a sprawling number of disconnected technologies, and often lags behind the data itself. In the Data 3.0 model, a multidimensional context is part of the product’s structure and lifecycle. It evolves as the product is built, run, used, and governed.
Nextdata’s autonomous data product lifecycle synchronously generates and aligns business and operational context around a single domain. This includes business-centric data, rich semantic definitions, relationships, rules, policies, and metadata, along with real-time operational metrics such as health, usage, data ROI, and cost.
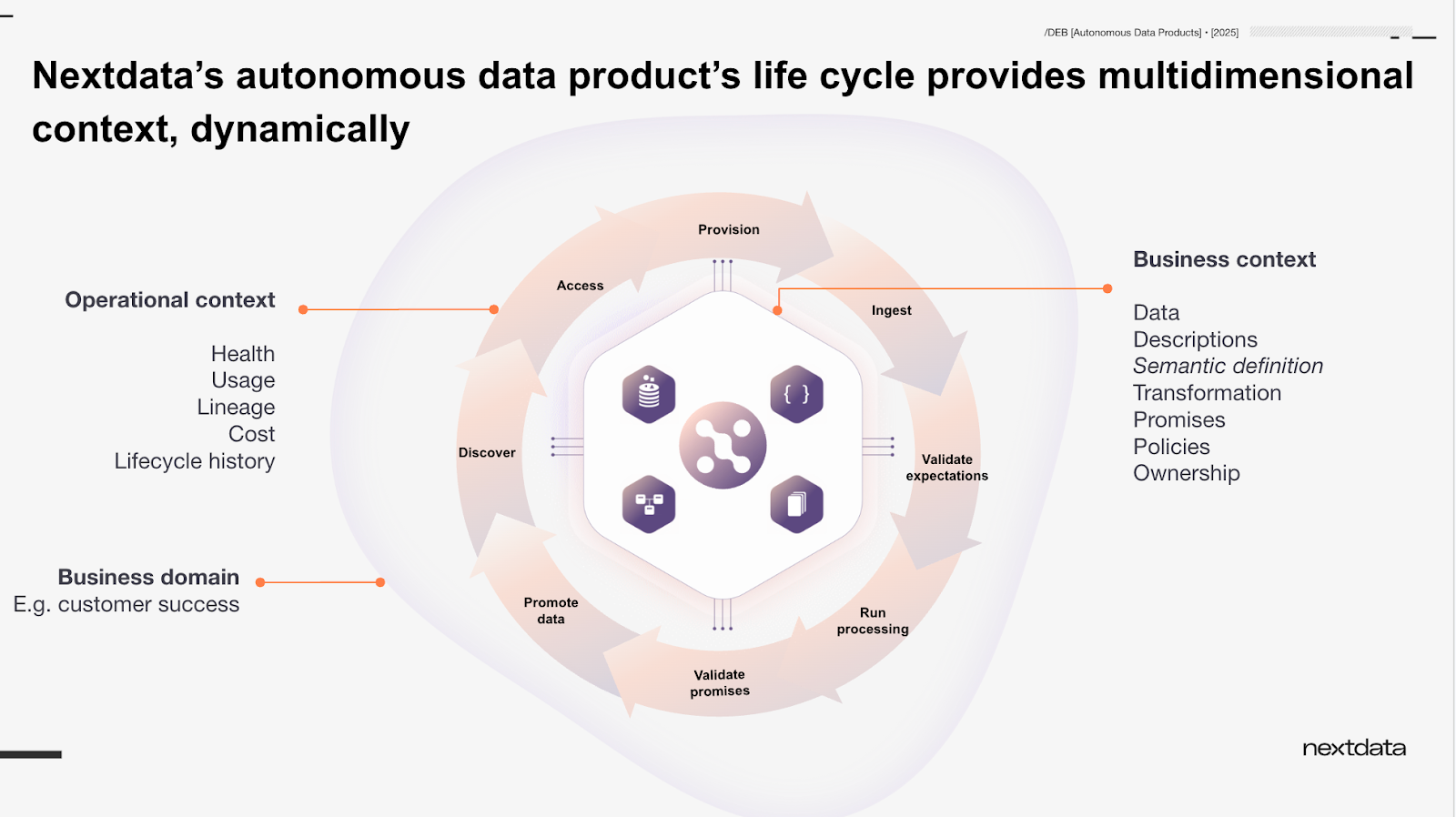
Together, the business and operational context of a domain guide agents to plan and execute their goals. Business agents focus on outcomes like improving customer satisfaction, while operational agents improve effectiveness safely and reliably.
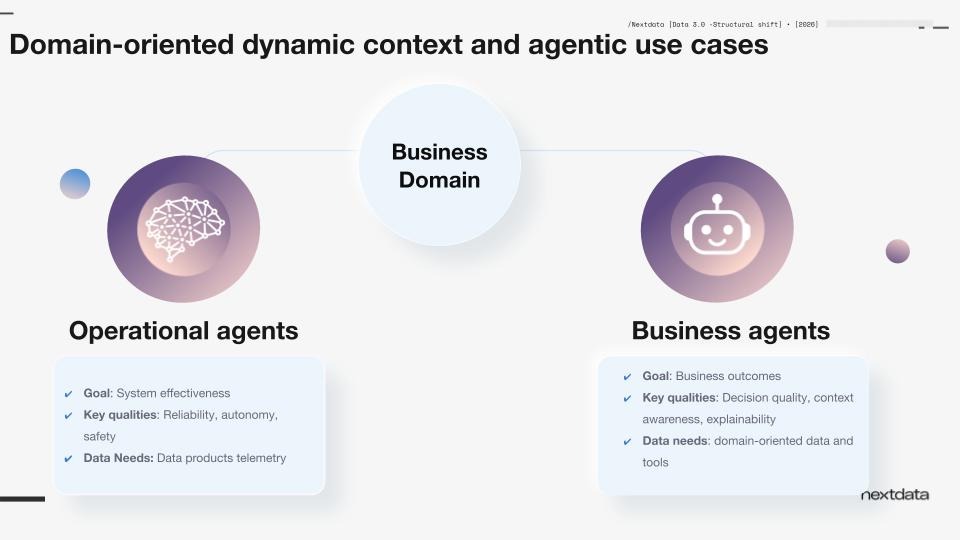
This is not yet the whole Data 3.0 story. But it is the first move, and arguably the most important one.
Because if the structure stays the same, the rest becomes decoration.
What we demonstrated in the webinar
The webinar demonstration showed three things.
First, the value of an existing mesh of autonomous data products. Jörg, in his role as CDO of Nextopia, a fictional e-commerce company that had just acquired a European startup, showed agents querying business questions across the mesh, discovering data products by intent, and accessing metadata such as lineage, usage patterns, quality signals, and domain ownership. All through a single MCP endpoint with no upfront system prompt configuration.
Second, building a new data product in minutes using the Nexty AI copilot. The new European sales transaction data needed to be integrated into the existing mesh. Nexty guided the process: identifying the semantic model from the source data, suggesting relevant glossary terms from the domain vocabulary, flagging the custom fiscal quarter definition (Q1 runs February–April, not January–March), and launching the data product with basic quality promises in place. The entire process took under three minutes.
Third, the practical difference semantics make. Without the glossary term defining the custom quarter, the agent calculated revenue using the wrong date range, confidently and incorrectly. With the glossary term in place, the same agent produced the right answer. The semantic enrichment changed the agent’s behavior without any change to the query or the prompt.
The computational governance layer was also demonstrated: a policy detecting PII exposure in a data product’s output, causing that data product to stop running and become unconsumable until the issue was resolved. Governance as a structural boundary not a post-hoc annotation.
What’s next
Data 3.0 implements six fundamental shifts to make data management ready and relevant for AI. This webinar covered the first: the structural shift. In future sessions, we will walk through the remaining five: modality, discoverability, orchestration, reasoning, and governance, and demonstrate how Nextdata OS brings each to life.
Based on audience questions, the next session will explore the discoverability shift — how agents find and use data by intent rather than by schema, and how ontologies, taxonomies, and semantic graphs fit into that picture.
More resources
If you missed the Nextdata Product Update: Data 3.0 - Domain-Oriented Semantic Context for AI Agents, you can watch the webinar recording here.
Also see how Data 3.0 makes enterprise data truly AI-ready you can reply Data 3.0 in action: What we showed at the Nextdata OS product update
And if you’re ready to see how Nextdata OS implements these shifts in your own environment, request a sandbox or get in touch at sales@nextdata.com

.png)





