

Data for AI
Autonomous Data Products
The self-driving data product: Why autonomy is the missing catalyst for Data 3.0.
In a recent episode of the Superdata Brothers show, Zhamak dug into a question many teams are wrestling with:
If we’ve built data products and adopted a product-centric mentality, why does execution still feel like a brittle hairball of pipelines, taking too long, with no AI-ready data in sight?
Her answer lands squarely in what comes after data mesh, and what defines Data 3.0: the shift from static, human-orchestrated data artifacts to autonomous, runtime data products.
The plateau we all recognize
When Zhamak introduced data mesh, it was in response to a pattern she saw repeatedly: as organizations increase the ambition of data usage, more sources, more use cases, more modalities, their speed of innovation plateaus instead of accelerating.
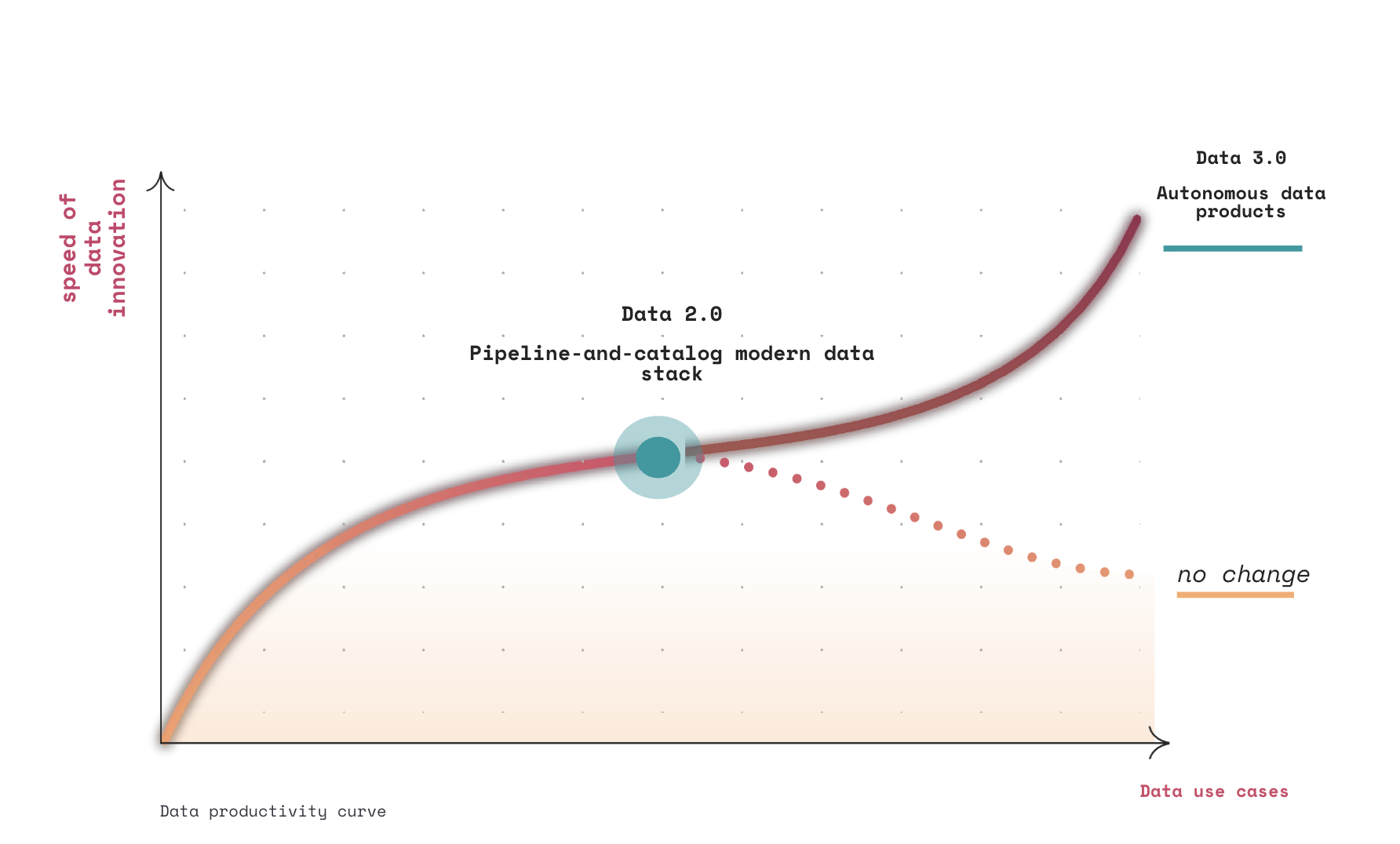
Data mesh reframed the operating model correctly. It pushed ownership to domains, emphasized data as a product, and introduced federated governance. Those ideas have largely landed.
But Data 3.0 begins where that story stalled.
As Zhamak explains, the lack of success at scale wasn’t because the principles were wrong. It was because the technology stack underneath never evolved to support them. What was missing was a catalyzing technology, one capable of collapsing a fragmented, storage-centric stack into a coherent, executable model of data value.
What autonomous data products aren’t
Let’s take a look at most data platforms today.
They resemble cars that require:
- One team to steer
- Another to manage the engine
- A third to monitor safety
- And a fourth to intervene after something breaks
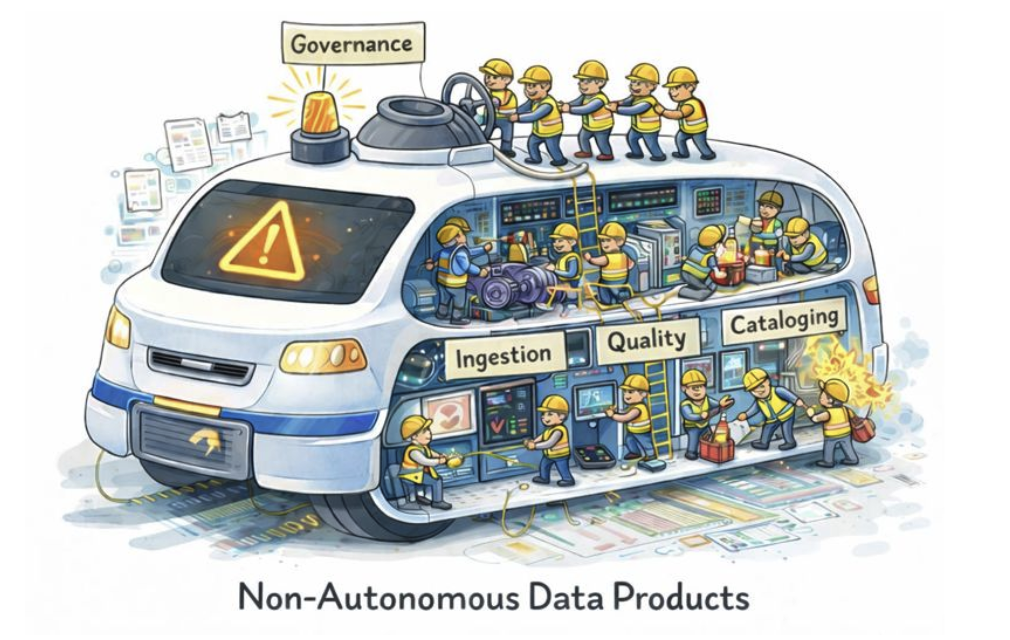
In Data 2.0, and even much of early data mesh, “data products” are closer to annotated artifacts than operational systems.
Data 3.0 changes the unit of value.
What autonomous data products actually are
Zhamak defines autonomy plainly: an entity that can achieve its purpose without constant human intervention. Not autonomy as a feature, autonomy with an objective.
Her go-to analogy is autonomous cars. A self-driving car isn’t autonomous because it has cameras or sensors. It’s autonomous because it can get you to a destination safely, continuously coordinating sensing, decision-making, and control, without a human orchestrating every move.
A truly autonomous car does contain many automated parts.
Planners, sensors, controllers, transmission logic, safety systems—each highly capable on its own. But none of them matter in isolation.
What makes the car autonomous is that these parts operate as one cohesive system, continuously coordinating toward a single objective:
Get you to a destination safely, under changing conditions, without human orchestration.
No one is manually stitching together perception, planning, control, and recovery at runtime. The intelligence is in the integration and execution, not the parts list.
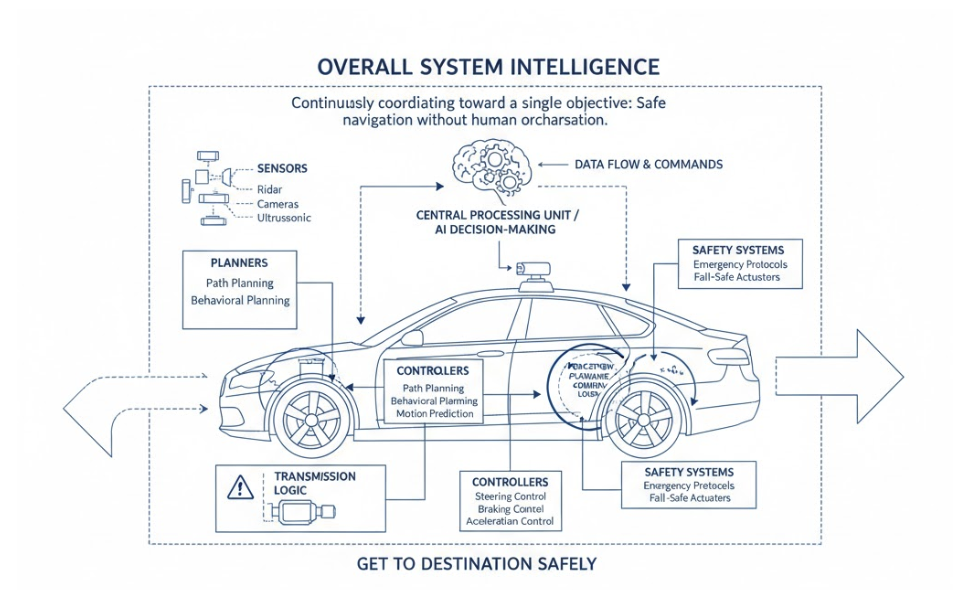
Autonomous data products follow the same pattern.
They are not a collection of automated tasks—ingestion here, quality checks there, governance over somewhere else. They are a single operational unit that knows:
- what part of the business it represents (its digital twin),
- what “correct” means for that domain,
- how it must govern itself,
- how it adapts as source data, policies, or consumers change
The objective is explicit:
Mirror a slice of the business faithfully and serve it, safely and continuously across analytical, operational, and AI use cases, without constant human intervention.
That’s the shift in Data 3.0.
Data 2.0 defined the parts list.
Data mesh envisioned a new socio-technical operating model.
Data 3.0 makes that operating model reality by making the unit of value an executing system - what we at Nextdata call an autonomous data product
As Zhamak frames it: autonomy isn’t a feature. It’s an outcome.
A data product is autonomous only if it can achieve its purpose on its own—coordinating its internal agents the way a self-driving car coordinates its subsystems. That’s what “autonomous” actually means.
Why Data 2.0 tooling can't get us there
Today, we try to assemble that outcome through handoffs:
- Ingestion teams, pipeline teams, quality tools, catalogs, semantic and context layers
- Governance applied after the fact
- Metadata scattered across systems, stitched together largely for documentation
- “Products” that are static outputs with a long list of dependencies, and go stale immediately
This model was workable when analytics was the primary consumer. It breaks down completely when AI agents, real-time systems, and automated decisioning enter the picture.
Data 3.0 requires data that behaves less like an asset you publish, and more like a service that runs itself.
The shift: from data artifacts to runtime autonomous products
This is where autonomous data products come in.
Instead of duct-taping layers and work products together, you package the production process itself, not just the output, into a runtime that can orchestrate execution, enforce contracts, emit observability signals, and control access, autonomously; A stateful runtime that manages its data, semantic and context around business domains.
That shift is the essence of Data 3.0:
From:
Data with metadata
To:
Data with a brain
Not static tables. Not pipelines plus dashboards. Executable, long-lived data products.
A slice of the layer cake, made operational
One of the clearest metaphors in the conversation is deceptively simple. Think of the data stack as a layer cake. Then take a slice, compute, pipelines, lineage, quality, access, and make that slice a single operational object.
Crucially, this is not a replatforming story.
Zhamak is explicit: you keep your storage, compute, and security foundations. Data 3.0 doesn’t replace your stack, it re-abstracts it. What changes is the control plane on top: data products that run as long-lived services, rather than static handoffs between tools.
What this looks like for data product developers
The developer experience Zhamak describes is intentionally focused on value, not plumbing:
- Start from a business use case and define the semantic model (storage-agnostic)
- Declare inputs, outputs, contracts, and quality expectations
- Write transformation logic in familiar tools (SQL, Spark, Python, etc.)
- Package it as a data product specification and run it
From there, the runtime takes over, provisioning infrastructure, orchestrating execution, enforcing contracts, emitting health and observability signals, and serving the semantic-aligned data and context in multiple modes: tables, MCP tools, vectors, etc. access.
This is Data 3.0 in practice: correctness, governance, and reliability continuously enforced at runtime, not policed after the fact.
AI changes the urgency—and the requirements
The timing isn’t accidental. AI needs rafts of data, but it needs more than that; it needs data that can be curated at machine speed, carry its own domain meaning, and be consumed in multiple ways without translation or rework. At the same time, enterprise data estates are fragmenting—more sources, more domains, more modalities—while the cost of coordinating humans across that sprawl keeps rising.
This is the tension the interview surfaces.
AI systems demand three things at once:
- Speed, so data can be produced and updated fast enough to keep models and agents relevant;
- Domain-oriented semantics and context, so outputs reflect how the business actually thinks and decides;
- And flexible modes of consumption, so the same data can serve analytics, APIs, vectors, and agent interactions without drift. The timing isn’t accidental.
Watch the interview
If you’re building toward domain ownership, federated governance, and AI-ready data, and still feeling the drag of pipelines, catalogs, and after-the-fact governance, this conversation is worth your time.
Watch the full interview with Zhamak on the Superdata Brothers show.
.jpg)

.jpg)
.png)




