
Data agents need more than context. They need a data architecture.
Every enterprise we talk to is building data agents. Most are hitting the same wall.
The demo works. The production system doesn't. Answers drift. Governance breaks down. The agent makes a decision no one can explain or reproduce. The data team scrambles to find out why.
The instinct is to fix the model. Tune the prompt. Adjust the retrieval. But the model is not the problem.
The problem is the data layer underneath it.
Agents are not SQL copilots
A SQL copilot helps a user write a query. A data agent has to decide what data to use, whether it is allowed to use it, whether the answer can be trusted, and what to do next.
That means a production data agent needs to know: Which data product is the right source for this business question? Is the data fresh enough? Is it approved for this use case? Does the output expose sensitive data? Can the result be reproduced?
These are not model questions. They are data architecture questions. A better model will not fix unclear ownership, missing semantics, stale data, or governance that exists only in documentation.
The lakehouse answer, and its limits
Databricks is proving what data agents need inside Databricks: rich context, trusted discovery, governance, identity, semantic understanding, verification, and multi-step reasoning. That is the right direction.
But most enterprises do not live inside one platform.
They run Snowflake and Databricks. They have warehouses, lakehouses, operational systems, SaaS applications, BI tools, catalogs, and policy engines. Finance data lives here. Customer data lives there. Business definitions are scattered across tools, spreadsheets, and the institutional memory of domain teams.
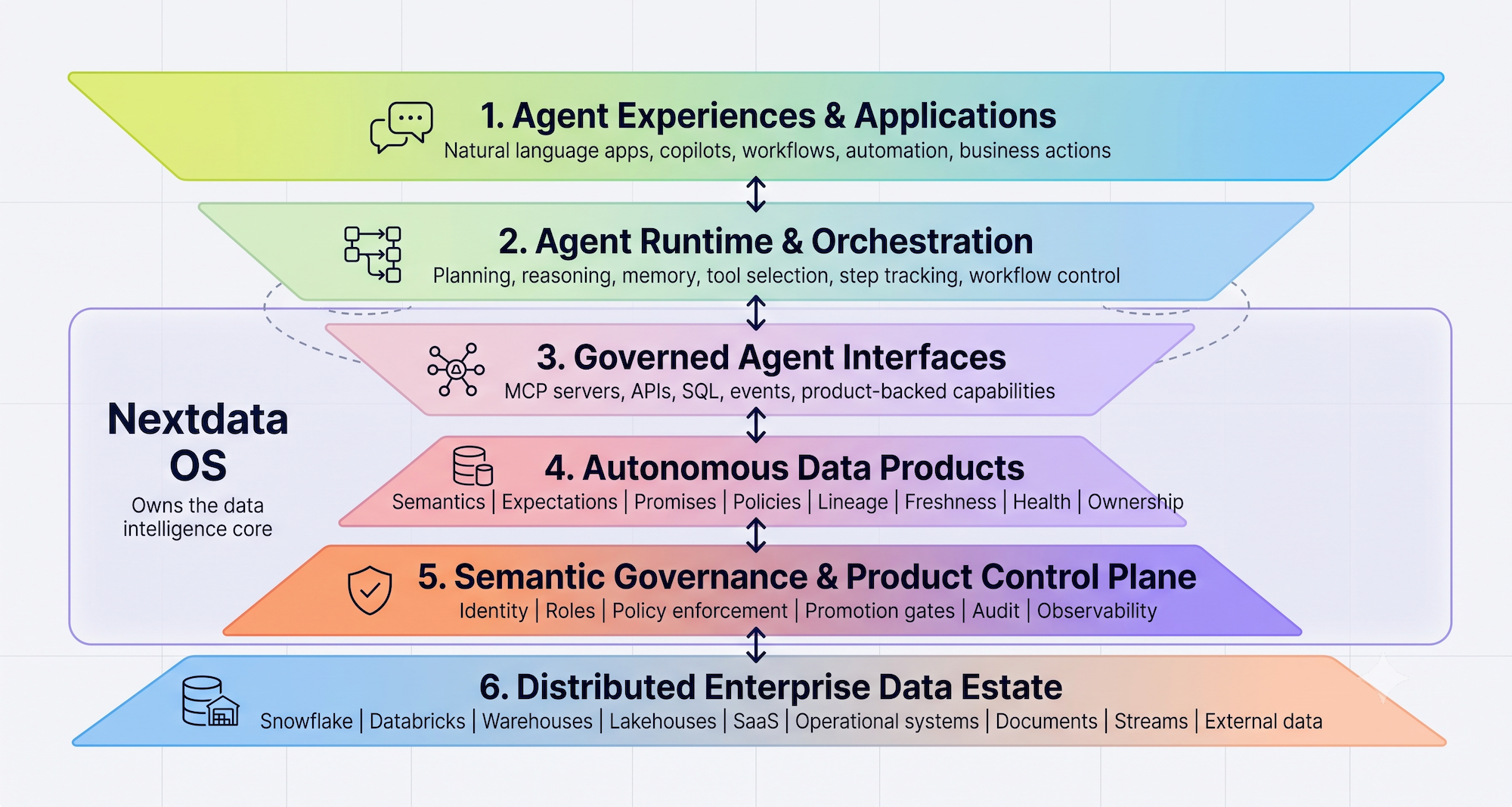
The agent still needs one coherent surface to operate on. That surface cannot be a prompt. It cannot be a manually curated catalog. It has to be structural.
Context has to travel with the data
The traditional data stack treats context as something added later. Data is produced first. Then someone registers it in a catalog. Someone adds descriptions. Someone maps glossary terms. Someone documents assumptions. And someone else tries to keep all of it current.
That worked imperfectly for humans. Humans compensate. They remember context. They know who to ask. They notice suspicious numbers.
Agents do not have that safety net.
For agentic interaction, context has to travel with the data. Semantics, quality, lineage, ownership, policy, freshness, and access rules need to be part of the data product lifecycle itself. Not layered on afterward.
This is the shift from schema-first to semantic-first. In a schema-first world, the table is the interface and meaning is external. In a semantic-first world, the data product is the interface and meaning is built in.
What we published
Today we are releasing our white paper: Building Data Agents Outside the Lakehouse Monolith.
It lays out what reliable, safe, and reproducible data agents actually require: discovery by business intent, semantic and glossary data products, contracts that define trust, policies that execute, safe promotion, governed MCP endpoints, central identity, and auditability across the full agentic interaction.
It includes a reference architecture built around a stable, governed data product layer that enterprise teams can apply regardless of which orchestrator or model they use. And it walks through a concrete example of what governed agentic interaction looks like in practice, from the first business question to a traceable, auditable answer.
The paper is written for data architects, platform engineers, and data leaders who are past the demo stage and building toward production.
If you are building data agents and your enterprise is not exclusively Databricks, this is for you.
Download the white paper: Building Data Agents Outside the Lakehouse Monolith →
.jpg)

.jpg)
.png)




