
AI-ready data products
From data chaos to agent-ready in a day
[A recap of the May 21st Nextdata webinar with Zhamak Dehghani and Sina Jahan]
The pressure on data leaders has never been greater. In our recent webinar, Zhamak and Sina laid out a clear-eyed diagnosis on why enterprises are struggling to connect their data to AI, and showed a working path forward.
Attendees joined from across the globe, from Sydney to Frankfurt to Abu Dhabi, which speaks to how universal this pain point has become.
Here's what we covered.
The CDO's expanding mandate, and growing pressure
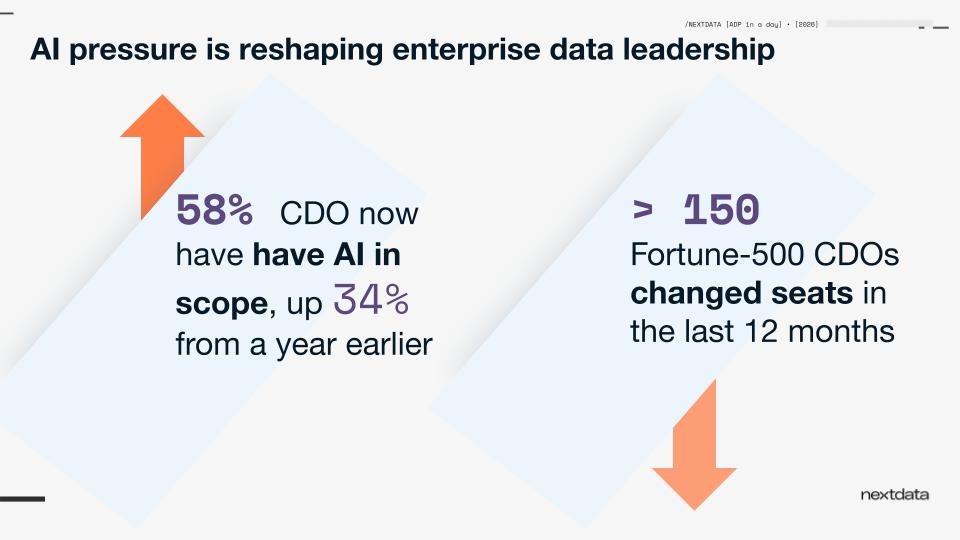
Zhamak opened with a candid observation on the environment data leaders are operating in. More than half of CDOs have recently had their charter expanded to include AI. They're not just responsible for data anymore, but for data for AI and for AI itself.
The evidence that the job is becoming untenable is already visible: a search of LinkedIn shows more than 150 CDOs of Fortune 500 companies have changed seats in the last year, either hired or departing.
The ambitions driving this churn aren't trivial. Drawing on published research from Gartner, BCG, and McKinsey, Zhamak highlighted the scale of transformation on the horizon:
- 70% of employee time will be automatable
- 40% of workforce tasks deemed "low value" will be replaced
- Business will move at least 50% faster
- 40% of enterprise applications will become agentic (a figure Zhamak called out as probably conservative)
These aren't soft predictions. They represent a fundamental shift in how work gets done — and data infrastructure has to keep pace.
The missing link between data and AI
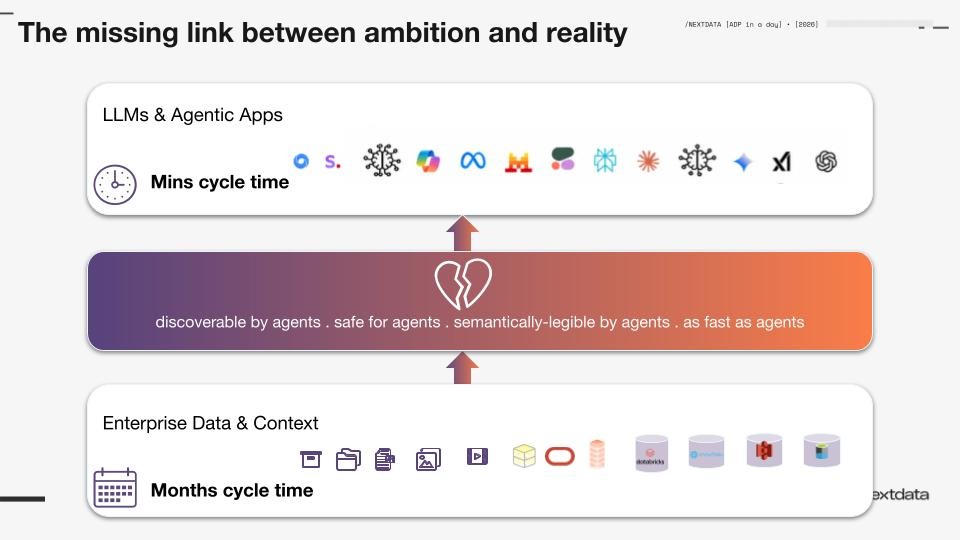
For those targets to become reality, Zhamak argued, there's a critical gap that needs to be bridged. At the top, you have LLMs capable of planning and executing tasks from a few prompts. At the bottom, you have sprawling data — structured and unstructured, sitting in warehouses, lake houses, and SaaS applications.
The missing middle layer needs to:
- Help agents discover relevant data
- Provide data that is safe to use and semantically understandable
- Do all of this fast
The cycle-time mismatch alone is staggering. Building an AI application can take hours. Getting data ready for it, at Fortune 500 companies, takes an average of 18 months and $1–1.5 million per data asset. That gap has to close.
The three questions organizations keep asking:
- How do we turn fragmented enterprise data into AI-ready data products?
- How do we do it two, twenty, or fifty times faster?
- How do we do it at scale, removing organizational bottlenecks?
What is an AI-ready data product?
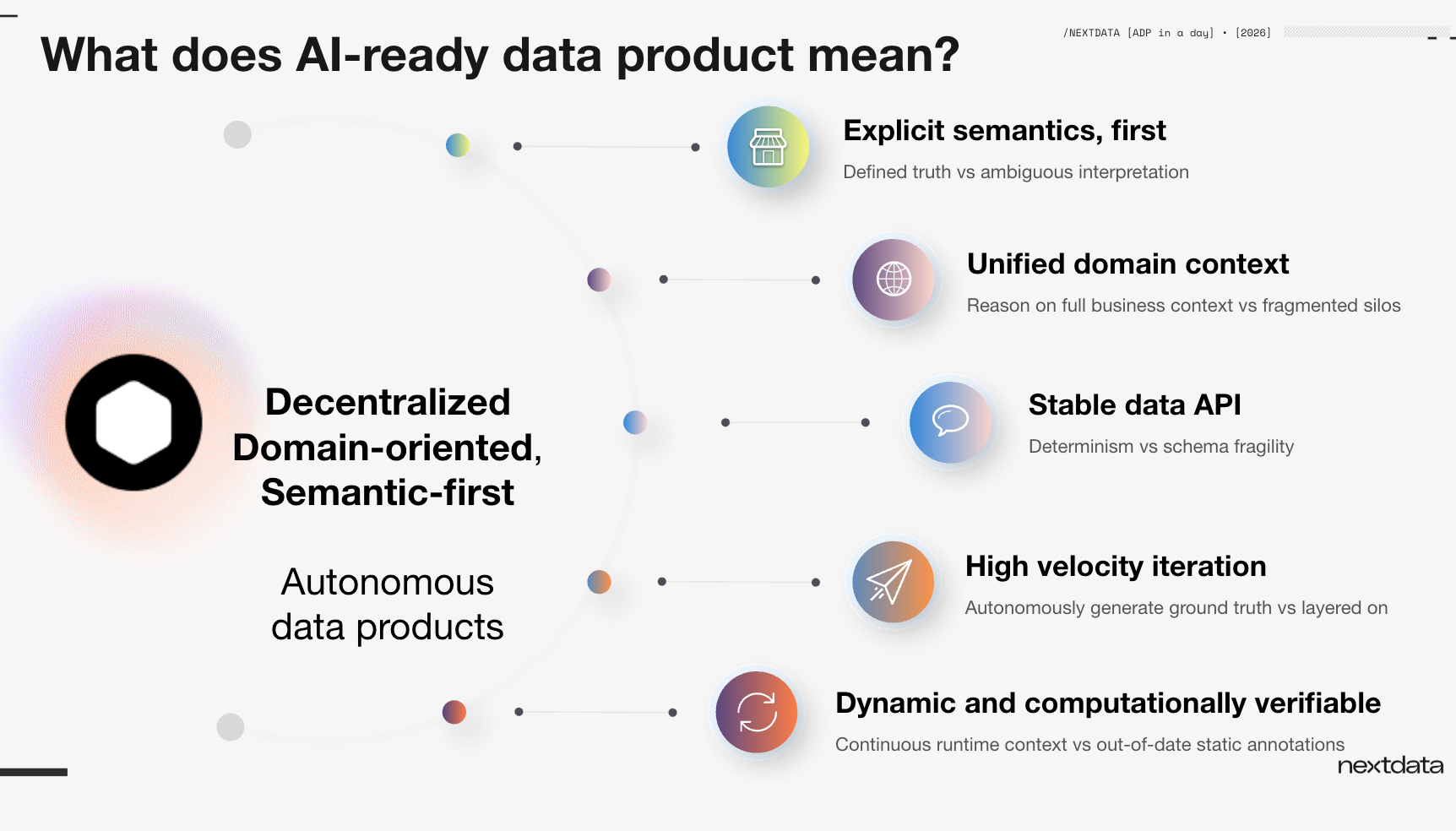
Zhamak offered a precise definition rather than a vague aspiration. An AI-ready data product isn't just data with a description attached — it's a running application that encapsulates and governs context at runtime. It has five critical characteristics:
1. Semantic first The product has an explicit semantic definition that establishes ground truth — not semantics extrapolated from data dumps after the fact. The difference matters: "quarterly revenue" is meaningless without knowing whether those quarters are fiscal or calendar.
2. Domain-bounded context The product is organized around the full business context of a domain. Not just the data itself, but the documentation, definitions, and language used in that business. This is a break from traditional data modeling, which has been optimized for query performance, not for communicating meaning.
3. Stable business APIs Access happens through stable, business-bounded APIs — not schemas. Today, dashboards drive schema-as-interface. That has to change. APIs that expose meaning, not just tables.
4. Speed Getting to these data products cannot take months. Agents won't wait. Business won't wait.
5. Computational governance The product must be verifiable at runtime — continuously and autonomously. This requires a fundamental shift from thinking about data as a schema to thinking about data as a service.
Demo: A data product up close
In the next demonstration Sina showed a Git-backed source code repository where a specification file packages the different aspects of a data product: metadata, transformation logic (in this case a Spark job, though it could be Snowflake, Redshift, or BigQuery), data inputs, and how the data is exposed to consumers.
The key insight: this particular product exposes its data in four ways — through Databricks, Snowflake, vector embeddings on Pinecone, and as MCP endpoints.
That last one is new. Until recently, APIs in this context were for application builders — a React app fetching sales data. Now those same APIs are exposed as MCP endpoints so that agents can talk to them directly.
What semantic means for agents
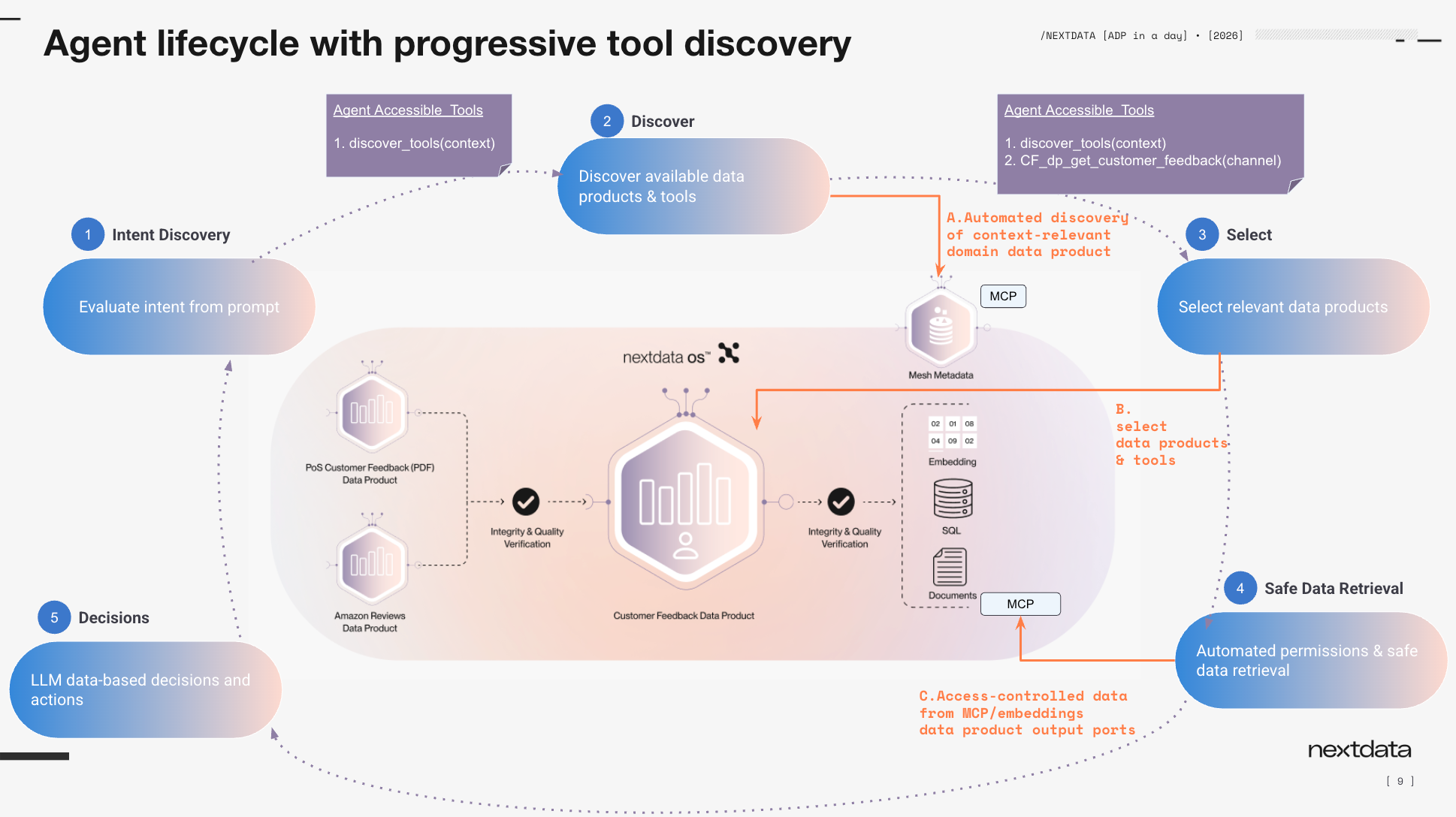
When an agent asks a question about sales data, it doesn't jump straight to the data. It first does tool discovery — fetching context from the mesh to understand what's available around sales, channels, and regions. Then it routes specifically to the right data product.
The semantic layer does the work humans used to do implicitly. When someone asks for "Q2 results," a human analyst would know the comAppany's fiscal year starts in April, not January. The semantic definitions built into the data product give that same knowledge to an agent — so it queries July-September, not April–June.
Glossary terms are themselves exposed as data products (linked in the lineage graph), and the whole semantic graph becomes navigable by both humans and agents.
Zooming out: The mesh view
When different parts of an organization each define their data as products using the same interface — regardless of whether they're on AWS, Azure, Snowflake, or Databricks — the result is a mesh of interconnected, semantically linked data products. The underlying technology stays where it is. The semantic links become traversable.
Zhamak: "The semantics are where the AI really needs to figure out what these concepts are so that it can answer questions more intelligently."
How to get there fast: The three-move strategy
Throwing AI at old processes won't create the exponential gains enterprises need. The problem is structural — data management was built for an era of dashboards, not agents. The pipeline of ingest → model → store → add metadata → govern → provision access → measure quality is months of manual handoffs between fragmented tools.
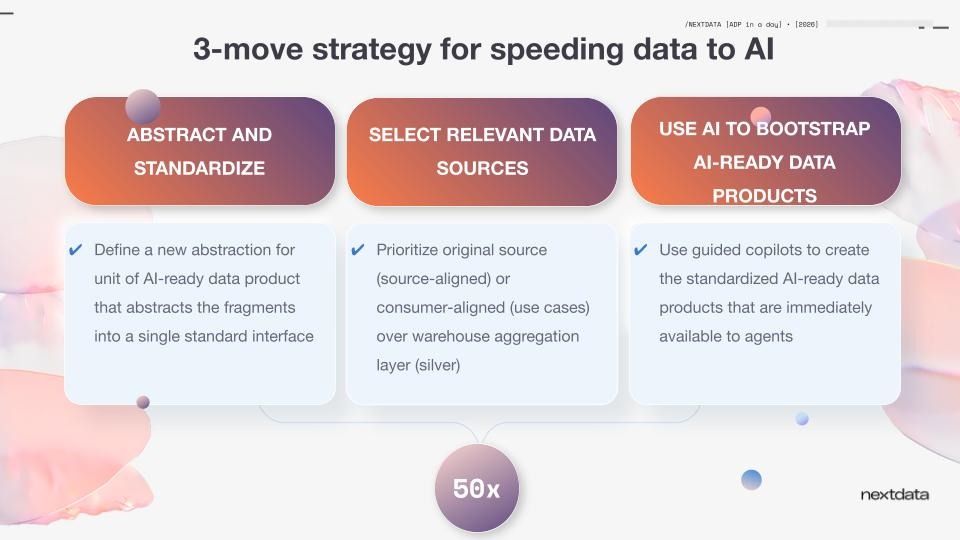
Zhamak's three-move strategy:
Move 1: Standardize and abstract complexity Create an interface standard that gives agents agility and predictability. Abstract the data mess behind a consistent interface before trying to automate it.
Move 2: Productize the right assets Not everything needs to be a data product. Focus effort on sources (where real signals live) and consumer-aligned data products. The "messy middle" — the layers of intermediate aggregation tables — is likely to be handled by LLMs in the future anyway, as context windows expand.
Move 3: Use AI to bootstrap Then apply AI-assisted tooling to generate those data products from selected assets — fast.
Demo: Two flavors of AI-assisted building
Nexty AI (Embedded copilot for non-technical users)
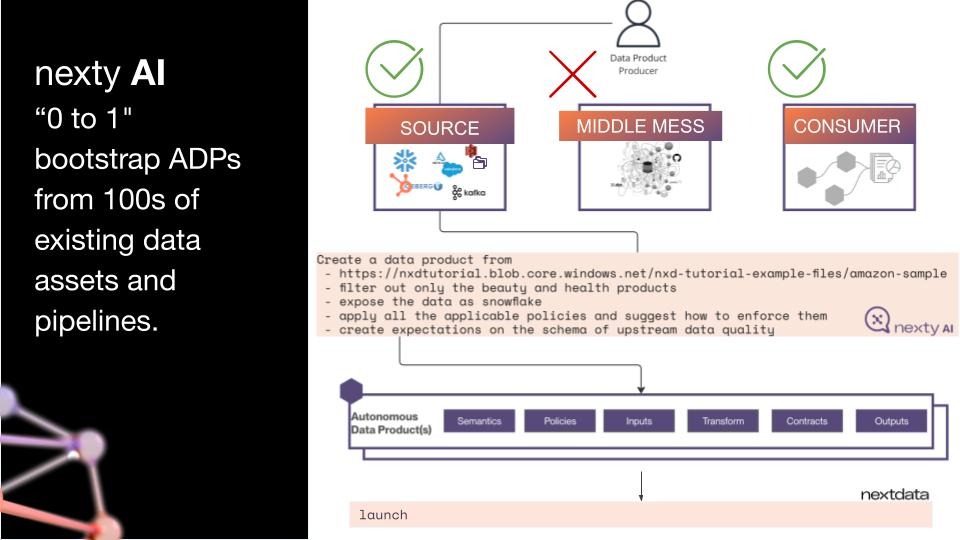
For teams that want to go from zero to a working data product without deep coding, Nexty AI is a built-in AI copilot. Point it at a data dump (S3, a CDC output, Fivetran, upstream APIs) and it walks you through building the product specification — models, inputs, promises, semantic definitions — with templating adapted to your domain and team's technology stack.
The result won't be perfect. But that's the point: solve the zero-to-one problem first. Launch something immature, then have domain experts — the people closest to the data — enrich the nuances.
Nexty AI (for power users)
For data engineers comfortable with Claude Code, Cursor, or Codex, Nexty AI Pro exposes a curated set of MCP endpoints and "skills" — codified learnings from field work with customers — that allow bootstrapping products from existing pipelines, datasets, or other data products. Same outcome, different interface.
Governance at scale: Computational, not documentation
The third challenge CDOs face is scale. How do you do all of this across an enterprise without recreating the centralization bottlenecks of the past?
Zhamak's concept of computational governance is the answer. Governance isn't documentation. It's code that runs on products.
Policies are defined at the mesh level, domain level, or subdomain level, and applied automatically to products matching certain criteria. They can govern:
- Data quality guarantees
- Cost of ingress
- Retention policies
- HIPAA, GXP, or custom compliance rules
The key shift: compliance is implemented at the time a product is built, and continuously enforced, not audited a year later in production. And because everything is built on a standard abstraction, you can get an aggregated view of health across the entire mesh.
A concrete example shown in the demo: a PII policy that says if a data product contains PII data, it must not be exposed to any LLMs. Violation consequences range from a warning to complete removal from the mesh until resolved.
Zhamak on why this abstraction matters: "The agent is dealing with one simple interface — the data product specification. The platform is abstracting all the complexity underneath: pipelines, terminology management, contracts, catalogs. That abstraction is what gives agents the determinism they need to work reliably."
Your options: Three paths forward
When evaluating how to move forward, Zhamak outlined three macro strategies:
Option 1: All-in with one vendor Go fully into Snowflake, Databricks, Fabric, etc. This works for organizations that can standardize the whole enterprise on a single stack. Less feasible or common at large, federated enterprises.
Option 2: Build it yourself Accept multi-stack reality and build your own integration layer. Valid but expensive — Zhamak and Sina both did this for years at Thoughtworks before concluding it needed to be commoditized.
Option 3: A purpose-built abstraction layer What Nextdata OS is: an opinionated, production-tested layer that handles the standardization, semantic modeling, and computational governance across any technology stack.
How to get started
For organizations ready to begin, the recommended approach is phased:
- Build a sandbox. You can't break organizational inertia without showing something tangible. A proof of concept with a handful of data products across one or two business units changes minds.
- Incubate. Expand to 30–100 data products with leading business units. Refine the model.
- Operationalize. Integrate into audit processes, access approval.
- Self-serve enablement by customizing and tuning the agentic UX for managing and using AI-ready data products for different teams and personas across the org.
At Nextdata, we partner with our customers to execute the full transformation journey in months, not years.
If you'd like to talk more to us about AI-ready data, here's a link to book a meeting with us.
.jpg)
.jpg)
.png)





